

Материалы ОП
“Если вы не знаете, как работают компиляторы, то вы не знаете, как работают компьютеры. Если вы не уверены на 100%, знаете ли вы, как работают компиляторы, то вы не знаете, как они работают.” — Стив Йегге
Вот так. Подумайте об этом. Неважно, новичок вы или опытный разработчик программного обеспечения: если вы не знаете, как работают компиляторы и интерпретаторы, то вы не знаете, как работают компьютеры. Все просто.
Итак, знаете ли вы, как работают компиляторы и интерпретаторы? И я имею в виду, уверены ли вы на 100%, что знаете, как они работают?

Или если вы не знаете и вас это действительно беспокоит.

Не волнуйтесь. Если вы останетесь и проработаете серию и построите интерпретатор и компилятор вместе со мной, вы в конце концов узнаете, как они работают. И вы тоже станете уверенным счастливым туристом. По крайней мере, я надеюсь на это.

Зачем изучать интерпретаторы и компиляторы? Я дам вам три причины.
- Чтобы написать интерпретатор или компилятор, вы должны обладать множеством технических навыков, которые вам необходимо использовать вместе. Написание интерпретатора или компилятора поможет вам улучшить эти навыки и стать лучшим разработчиком программного обеспечения. Кроме того, навыки, которые вы приобретете, полезны при написании любого программного обеспечения, а не только интерпретаторов или компиляторов.
- Вы действительно хотите знать, как работают компьютеры. Часто интерпретаторы и компиляторы выглядят как магия. И вам не должно быть комфортно с этой магией. Вы хотите демистифицировать процесс создания интерпретатора и компилятора, понять, как они работают, и получить контроль над вещами.
- Вы хотите создать свой собственный язык программирования или предметно-ориентированный язык. Если вы создадите его, вам также нужно будет создать либо интерпретатор, либо компилятор для него. В последнее время наблюдается возрождение интереса к новым языкам программирования. И вы можете видеть, как новый язык программирования появляется почти каждый день: Elixir, Go, Rust, и это лишь некоторые из них.
Хорошо, но что такое интерпретаторы и компиляторы?
Цель интерпретатора или компилятора — перевести исходную программу на некотором языке высокого уровня в некоторую другую форму. Довольно расплывчато, не правда ли? Просто наберитесь терпения, позже в этой серии вы узнаете, во что именно переводится исходная программа.
В этот момент вам также может быть интересно, в чем разница между интерпретатором и компилятором. Для целей этой серии давайте согласимся, что если транслятор переводит исходную программу на машинный язык, то это компилятор. Если транслятор обрабатывает и выполняет исходную программу, не переводя ее сначала на машинный язык, то это интерпретатор. Визуально это выглядит примерно так:
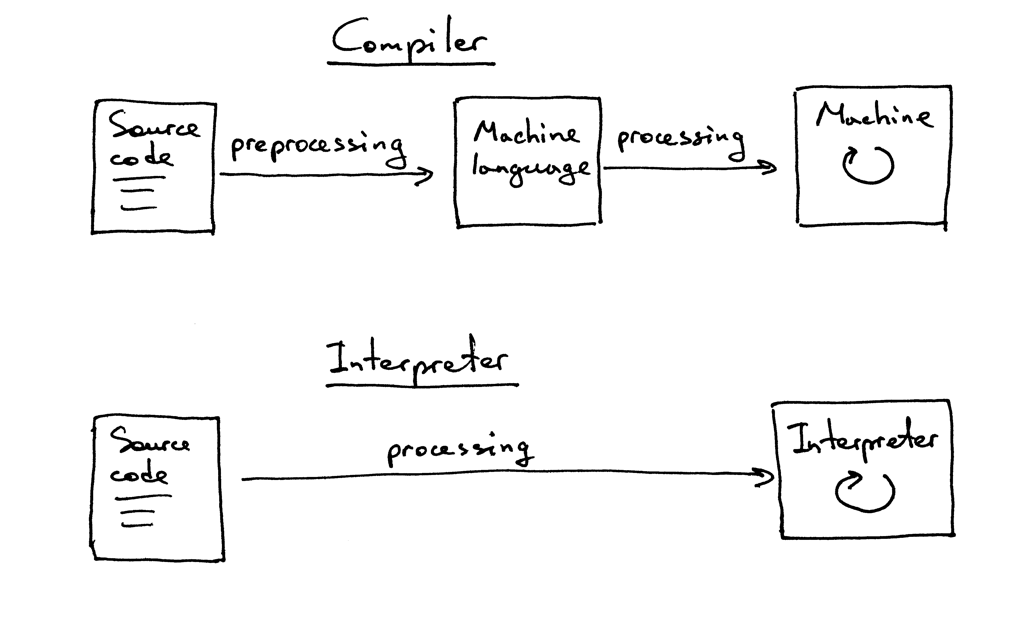
Я надеюсь, что теперь вы убеждены, что действительно хотите изучать и создавать интерпретатор и компилятор. Чего вы можете ожидать от этой серии об интерпретаторах?
Вот в чем дело. Мы с вами собираемся создать простой интерпретатор для большого подмножества языка Pascal. В конце этой серии у вас будет работающий интерпретатор Pascal и отладчик исходного уровня, такой как pdb в Python.
Вы можете спросить, почему Pascal? Во-первых, это не выдуманный язык, который я придумал специально для этой серии: это настоящий язык программирования, который имеет много важных языковых конструкций. И в некоторых старых, но полезных книгах по информатике в примерах используется язык программирования Pascal (я понимаю, что это не особенно убедительная причина для выбора языка для создания интерпретатора, но я подумал, что было бы неплохо для разнообразия изучить неосновной язык :)
Вот пример функции факториала на Pascal, которую вы сможете интерпретировать с помощью своего собственного интерпретатора и отлаживать с помощью интерактивного отладчика исходного уровня, который вы создадите по ходу дела:
program factorial;
function factorial(n: integer): longint;
begin
if n = 0 then
factorial := 1
else
factorial := n * factorial(n - 1);
end;
var
n: integer;
begin
for n := 0 to 16 do
writeln(n, '! = ', factorial(n));
end.
Языком реализации интерпретатора Pascal будет Python, но вы можете использовать любой язык, который захотите, потому что представленные идеи не зависят от какого-либо конкретного языка реализации. Хорошо, давайте перейдем к делу. На старт, внимание, марш!
Вы начнете свое первое знакомство с интерпретаторами и компиляторами с написания простого интерпретатора арифметических выражений, также известного как калькулятор. Сегодня цель довольно минималистична: заставить ваш калькулятор обрабатывать сложение двух однозначных целых чисел, таких как 3+5. Вот исходный код для вашего калькулятора, извините, интерпретатора:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, EOF = 'INTEGER', 'PLUS', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, PLUS, or EOF
self.type = type
# token value: 0, 1, 2. 3, 4, 5, 6, 7, 8, 9, '+', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS '+')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Interpreter(object):
def __init__(self, text):
# client string input, e.g. "3+5"
self.text = text
# self.pos is an index into self.text
self.pos = 0
# current token instance
self.current_token = None
def error(self):
raise Exception('Error parsing input')
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
text = self.text
# is self.pos index past the end of the self.text ?
# if so, then return EOF token because there is no more
# input left to convert into tokens
if self.pos > len(text) - 1:
return Token(EOF, None)
# get a character at the position self.pos and decide
# what token to create based on the single character
current_char = text[self.pos]
# if the character is a digit then convert it to
# integer, create an INTEGER token, increment self.pos
# index to point to the next character after the digit,
# and return the INTEGER token
if current_char.isdigit():
token = Token(INTEGER, int(current_char))
self.pos += 1
return token
if current_char == '+':
token = Token(PLUS, current_char)
self.pos += 1
return token
self.error()
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.get_next_token()
else:
self.error()
def expr(self):
"""expr -> INTEGER PLUS INTEGER"""
# set current token to the first token taken from the input
self.current_token = self.get_next_token()
# we expect the current token to be a single-digit integer
left = self.current_token
self.eat(INTEGER)
# we expect the current token to be a '+' token
op = self.current_token
self.eat(PLUS)
# we expect the current token to be a single-digit integer
right = self.current_token
self.eat(INTEGER)
# after the above call the self.current_token is set to
# EOF token
# at this point INTEGER PLUS INTEGER sequence of tokens
# has been successfully found and the method can just
# return the result of adding two integers, thus
# effectively interpreting client input
result = left.value + right.value
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
interpreter = Interpreter(text)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
Сохраните приведенный выше код в файл calc1.py или загрузите его непосредственно с GitHub. Прежде чем вы начнете копаться в коде, запустите калькулятор в командной строке и посмотрите, как он работает. Поиграйте с ним! Вот пример сеанса на моем ноутбуке (если вы хотите запустить калькулятор под Python3, вам нужно будет заменить raw_input на input):
$ python calc1.py
calc> 3+4
7
calc> 3+5
8
calc> 3+9
12
calc>
Чтобы ваш простой калькулятор работал правильно, не выдавая исключений, ваш ввод должен соответствовать определенным правилам:
- В вводе допускаются только однозначные целые числа
- В настоящее время поддерживается только арифметическая операция сложения
- В вводе нигде не допускаются символы пробела
Эти ограничения необходимы для упрощения калькулятора. Не волнуйтесь, вы довольно скоро сделаете его довольно сложным.
Хорошо, теперь давайте углубимся и посмотрим, как работает ваш интерпретатор и как он вычисляет арифметические выражения.
Когда вы вводите выражение 3+5 в командной строке, ваш интерпретатор получает строку “3+5”. Чтобы интерпретатор действительно понял, что делать с этой строкой, ему сначала нужно разбить ввод “3+5” на компоненты, называемые токенами. Токен — это объект, который имеет тип и значение. Например, для строки “3” типом токена будет INTEGER, а соответствующим значением будет целое число 3.
Процесс разбиения входной строки на токены называется лексическим анализом. Итак, первый шаг, который должен сделать ваш интерпретатор, — это прочитать ввод символов и преобразовать его в поток токенов. Часть интерпретатора, которая это делает, называется лексическим анализатором, или сокращенно лексером. Вы также можете встретить другие названия для того же компонента, например, сканер или токенизатор. Все они означают одно и то же: часть вашего интерпретатора или компилятора, которая преобразует ввод символов в поток токенов.
Метод get_next_token класса Interpreter — это ваш лексический анализатор. Каждый раз, когда вы вызываете его, вы получаете следующий токен, созданный из ввода символов, переданного интерпретатору. Давайте внимательнее посмотрим на сам метод и посмотрим, как он на самом деле выполняет свою работу по преобразованию символов в токены. Ввод хранится в переменной text, которая содержит входную строку, а pos — это индекс в этой строке (представьте строку как массив символов). pos изначально установлен в 0 и указывает на символ ‘3’. Метод сначала проверяет, является ли символ цифрой, и если да, то он увеличивает pos и возвращает экземпляр токена с типом INTEGER и значением, установленным в целочисленное значение строки ‘3’, которое является целым числом 3:
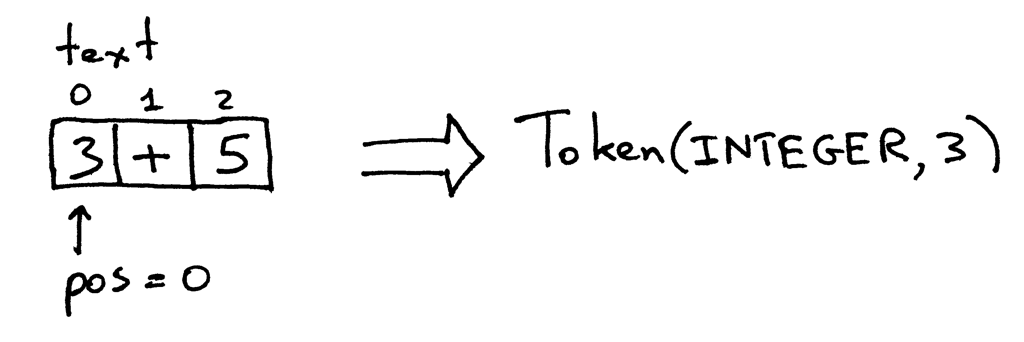
Теперь pos указывает на символ ‘+’ в тексте. В следующий раз, когда вы вызываете метод, он проверяет, является ли символ в позиции pos цифрой, а затем проверяет, является ли символ знаком плюс, которым он и является. В результате метод увеличивает pos и возвращает вновь созданный токен с типом PLUS и значением ‘+’:
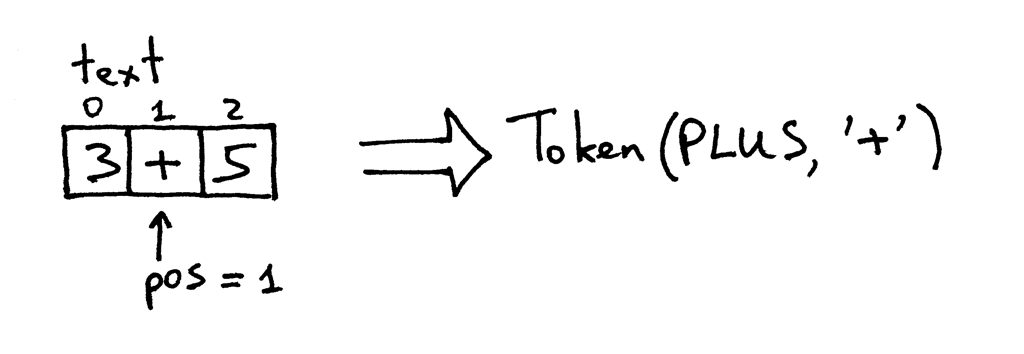
Теперь pos указывает на символ ‘5’. Когда вы снова вызываете метод get_next_token, метод проверяет, является ли он цифрой, которой он и является, поэтому он увеличивает pos и возвращает новый токен INTEGER со значением токена, установленным в целое число 5:
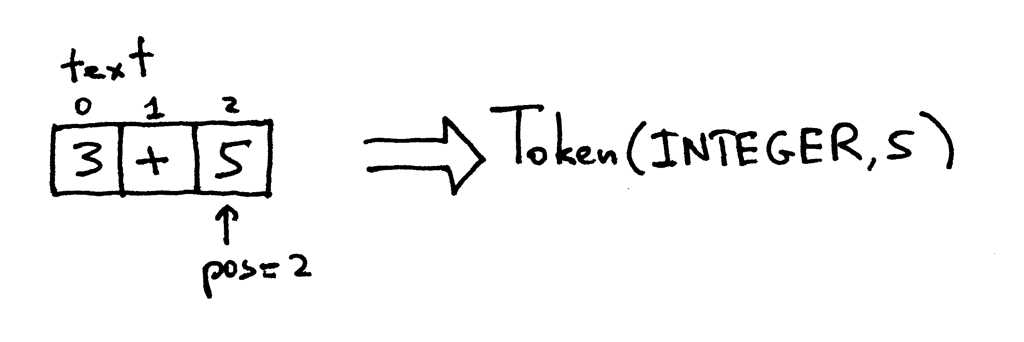
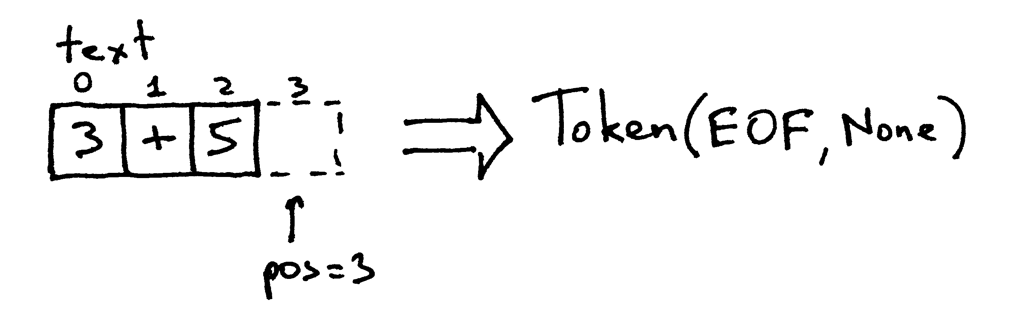
Поскольку индекс pos теперь находится за концом строки “3+5”, метод get_next_token возвращает токен EOF каждый раз, когда вы его вызываете:
Попробуйте сами и убедитесь, как работает компонент лексера вашего калькулятора:
>>> from calc1 import Interpreter
>>>
>>> interpreter = Interpreter('3+5')
>>> interpreter.get_next_token()
Token(INTEGER, 3)
>>>
>>> interpreter.get_next_token()
Token(PLUS, '+')
>>>
>>> interpreter.get_next_token()
Token(INTEGER, 5)
>>>
>>> interpreter.get_next_token()
Token(EOF, None)
>>>
Итак, теперь, когда ваш интерпретатор имеет доступ к потоку токенов, составленному из входных символов, интерпретатору нужно что-то с этим сделать: ему нужно найти структуру в плоском потоке токенов, который он получает от лексера get_next_token. Ваш интерпретатор ожидает найти следующую структуру в этом потоке: INTEGER -> PLUS -> INTEGER. То есть он пытается найти последовательность токенов: целое число, за которым следует знак плюс, за которым следует целое число.
Метод, отвечающий за поиск и интерпретацию этой структуры, — expr. Этот метод проверяет, действительно ли последовательность токенов соответствует ожидаемой последовательности токенов, т. е. INTEGER -> PLUS -> INTEGER. После успешного подтверждения структуры он генерирует результат, складывая значение токена слева от PLUS и справа от PLUS, тем самым успешно интерпретируя арифметическое выражение, которое вы передали интерпретатору.
Сам метод expr использует вспомогательный метод eat для проверки того, что тип токена, переданный методу eat, соответствует текущему типу токена. После сопоставления переданного типа токена метод eat получает следующий токен и присваивает его переменной current_token, тем самым эффективно «съедая» текущий сопоставленный токен и продвигая воображаемый указатель в потоке токенов. Если структура в потоке токенов не соответствует ожидаемой последовательности токенов INTEGER PLUS INTEGER, метод eat выдает исключение.
Давайте подытожим, что делает ваш интерпретатор для вычисления арифметического выражения:
- Интерпретатор принимает входную строку, скажем, “3+5”
- Интерпретатор вызывает метод expr для поиска структуры в потоке токенов, возвращаемом лексическим анализатором get_next_token. Структура, которую он пытается найти, имеет вид INTEGER PLUS INTEGER. После подтверждения структуры он интерпретирует ввод, складывая значения двух токенов INTEGER, потому что интерпретатору в этот момент ясно, что ему нужно сложить два целых числа, 3 и 5.
Поздравьте себя. Вы только что узнали, как построить свой самый первый интерпретатор!
Теперь пришло время для упражнений.

Вы же не думали, что просто прочитаете эту статью и этого будет достаточно, не так ли? Хорошо, запачкайте руки и выполните следующие упражнения:
- Измените код, чтобы разрешить многозначные целые числа во входных данных, например “12+3”
- Добавьте метод, который пропускает символы пробела, чтобы ваш калькулятор мог обрабатывать входные данные с символами пробела, например ” 12 + 3”
- Измените код и вместо ‘+’ обрабатывайте ‘-’ для вычисления вычитаний, таких как “7-5”
Проверьте свое понимание
- Что такое интерпретатор?
- Что такое компилятор?
- В чем разница между интерпретатором и компилятором?
- Что такое токен?
- Как называется процесс, который разбивает ввод на токены?
- Как называется часть интерпретатора, которая выполняет лексический анализ?
- Какие другие распространенные названия у этой части интерпретатора или компилятора?
Литература
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
- Modern Compiler Implementation in Java
- Modern Compiler Design
- Compilers: Principles, Techniques, and Tools (2nd Edition)