

Материалы ОП
“Обучение подобно гребле против течения: не продвигаться вперед — значит откатываться назад.” — Китайская пословица
Сегодня мы расширим наш интерпретатор, чтобы он распознавал вызовы процедур. Надеюсь, к настоящему моменту вы уже размяли свои навыки программирования и готовы к этому шагу. Это необходимый шаг для нас, прежде чем мы сможем научиться выполнять вызовы процедур, что будет темой, которую мы подробно рассмотрим в будущих статьях.
Цель на сегодня — убедиться, что когда наш интерпретатор читает программу с вызовом процедуры, парсер строит абстрактное синтаксическое дерево (AST) с новым узлом дерева для вызова процедуры, а семантический анализатор и интерпретатор не выдают никаких ошибок при обходе AST.
Давайте посмотрим на пример программы, содержащей вызов процедуры Alpha(3 + 5, 7):

Наша задача на сегодня — сделать так, чтобы наш интерпретатор распознавал программы, подобные приведенной выше.
Как и в случае с любой новой функцией, нам необходимо обновить различные компоненты интерпретатора, чтобы поддержать эту функцию. Давайте рассмотрим каждый из этих компонентов по очереди.
Прежде всего, нам нужно обновить парсер. Вот список всех изменений парсера, которые нам нужно внести, чтобы иметь возможность разбирать вызовы процедур и строить правильное AST:
- Нам нужно добавить новый узел AST для представления вызова процедуры.
- Нам нужно добавить новое правило грамматики для операторов вызова процедуры; затем нам нужно реализовать это правило в коде.
- Нам нужно расширить правило грамматики statement, чтобы включить правило для операторов вызова процедуры, и обновить метод statement, чтобы отразить изменения в грамматике.
1. Давайте начнем с создания отдельного класса для представления узла AST вызова процедуры. Назовем класс ProcedureCall:
class ProcedureCall(AST):
def __init__(self, proc_name, actual_params, token):
self.proc_name = proc_name
self.actual_params = actual_params # a list of AST nodes
self.token = token
Конструктор класса ProcedureCall принимает три параметра: имя процедуры, список фактических параметров (a.k.a аргументов) и токен. Ничего особенного, просто достаточно информации, чтобы зафиксировать конкретный вызов процедуры.
2. Следующий шаг, который нам нужно предпринять, — это расширить нашу грамматику и добавить правило грамматики для вызовов процедур. Назовем правило proccall_statement:
proccall_statement : ID LPAREN (expr (COMMA expr)*)? RPAREN
Вот соответствующая синтаксическая диаграмма для этого правила:
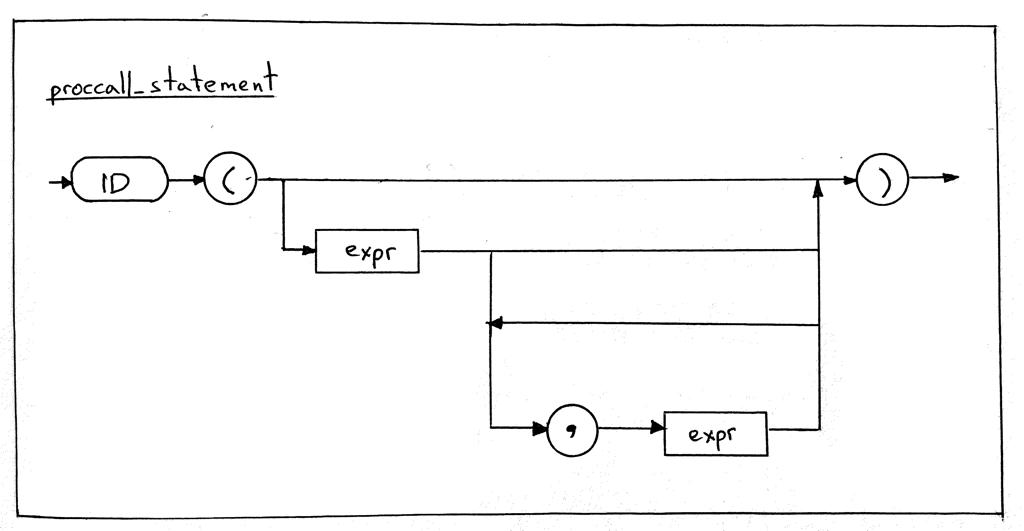
Из диаграммы выше видно, что вызов процедуры — это токен ID, за которым следует левая скобка, за которой следует ноль или более выражений, разделенных запятыми, за которыми следует правая скобка. Вот некоторые примеры вызовов процедур, которые соответствуют этому правилу:
Alpha();
Alpha(1);
Alpha(3 + 5, 7);
Далее давайте реализуем это правило в нашем парсере, добавив метод proccall_statement:
def proccall_statement(self):
"""proccall_statement : ID LPAREN (expr (COMMA expr)*)? RPAREN"""
token = self.current_token
proc_name = self.current_token.value
self.eat(TokenType.ID)
self.eat(TokenType.LPAREN)
actual_params = []
if self.current_token.type != TokenType.RPAREN:
node = self.expr()
actual_params.append(node)
while self.current_token.type == TokenType.COMMA:
self.eat(TokenType.COMMA)
node = self.expr()
actual_params.append(node)
self.eat(TokenType.RPAREN)
node = ProcedureCall(
proc_name=proc_name,
actual_params=actual_params,
token=token,
)
return node
Реализация довольно проста и следует правилу грамматики: метод разбирает вызов процедуры и возвращает новый узел AST ProcedureCall.
3. И последние изменения в парсере, которые нам нужно внести: расширить правило грамматики statement, добавив правило proccall_statement, и обновить метод statement, чтобы вызвать метод proccall_statement.
Вот обновленное правило грамматики statement, которое включает правило proccall_statement:
statement : compound_statement
| proccall_statement
| assignment_statement
| empty
Теперь у нас возникла сложная ситуация, когда у нас есть два правила грамматики — proccall_statement и assignment_statement — которые начинаются с одного и того же токена, токена ID. Вот их полные правила грамматики, собранные вместе для сравнения:
proccall_statement : ID LPAREN (expr (COMMA expr)*)? RPAREN
assignment_statement : variable ASSIGN expr
variable: ID
Как отличить вызов процедуры от присваивания в таком случае? Это оба оператора, и оба начинаются с токена ID. В фрагменте кода ниже значение (лексема) токена ID для обоих операторов — foo:
foo(); { вызов процедуры }
foo := 5; { присваивание }
Парсер должен распознавать foo(); выше как вызов процедуры, а foo := 5; как присваивание. Но что мы можем сделать, чтобы помочь парсеру различать вызовы процедур и присваивания? Согласно нашему новому правилу грамматики proccall_statement, вызовы процедур начинаются с токена ID, за которым следует левая скобка. И это то, на что мы будем полагаться в парсере, чтобы различать вызовы процедур и присваивания переменным — наличие левой скобки после токена ID:
if (self.current_token.type == TokenType.ID and
self.lexer.current_char == '('
):
node = self.proccall_statement()
elif self.current_token.type == TokenType.ID:
node = self.assignment_statement()
Как вы можете видеть в коде выше, сначала мы проверяем, является ли текущий токен токеном ID, а затем проверяем, следует ли за ним левая скобка. Если да, то мы разбираем вызов процедуры, в противном случае мы разбираем оператор присваивания.
Вот полная обновленная версия метода statement:
def statement(self):
"""
statement : compound_statement
| proccall_statement
| assignment_statement
| empty
"""
if self.current_token.type == TokenType.BEGIN:
node = self.compound_statement()
elif (self.current_token.type == TokenType.ID and
self.lexer.current_char == '('
):
node = self.proccall_statement()
elif self.current_token.type == TokenType.ID:
node = self.assignment_statement()
else:
node = self.empty()
return node
Пока все хорошо. Теперь парсер может разбирать вызовы процедур. Однако следует помнить, что процедуры Pascal не имеют операторов возврата, поэтому мы не можем использовать вызовы процедур в выражениях. Например, следующий пример не будет работать, если Alpha — это процедура:
x := 10 * Alpha(3 + 5, 7);
Вот почему мы добавили proccall_statement только в метод statements и больше нигде. Не беспокойтесь, позже в этой серии мы узнаем о функциях Pascal, которые могут возвращать значения и также могут использоваться в выражениях и присваиваниях.
Это все изменения для нашего парсера. Далее идут изменения семантического анализатора.
Единственное изменение, которое нам нужно внести в наш семантический анализатор для поддержки вызовов процедур, — это добавить метод visit_ProcedureCall:
def visit_ProcedureCall(self, node):
for param_node in node.actual_params:
self.visit(param_node)
Все, что делает метод, — это перебирает список фактических параметров, переданных вызову процедуры, и посещает каждый узел параметра по очереди. Важно не забыть посетить каждый узел параметра, потому что каждый узел параметра сам по себе является поддеревом AST.
Это было легко, не правда ли? Хорошо, теперь переходим к изменениям интерпретатора.
Изменения интерпретатора, по сравнению с изменениями семантического анализатора, еще проще — нам нужно только добавить пустой метод visit_ProcedureCall в класс Interpreter:
def visit_ProcedureCall(self, node):
pass
Со всеми вышеуказанными изменениями у нас теперь есть интерпретатор, который может распознавать вызовы процедур. И под этим я подразумеваю, что интерпретатор может разбирать вызовы процедур и создавать AST с узлами ProcedureCall, соответствующими этим вызовам процедур. Вот пример программы Pascal, которую мы видели в начале статьи и которую мы хотим протестировать на нашем интерпретаторе:
program Main;
procedure Alpha(a : integer; b : integer);
var x : integer;
begin
x := (a + b ) * 2;
end;
begin { Main }
Alpha(3 + 5, 7); { вызов процедуры }
end. { Main }
Загрузите приведенную выше программу с GitHub или сохраните код в файл part16.pas.
Убедитесь сами, что запуск нашего обновленного интерпретатора с файлом part16.pas в качестве входного файла не вызывает никаких ошибок:
$ python spi.py part16.pas
$
Пока все хорошо, но отсутствие вывода не так уж и интересно. :) Давайте немного визуализируем и сгенерируем AST для приведенной выше программы, а затем визуализируем AST с помощью обновленной версии утилиты genastdot.py :
$ python genastdot.py part16.pas > ast.dot && dot -Tpng -o ast.png ast.dot
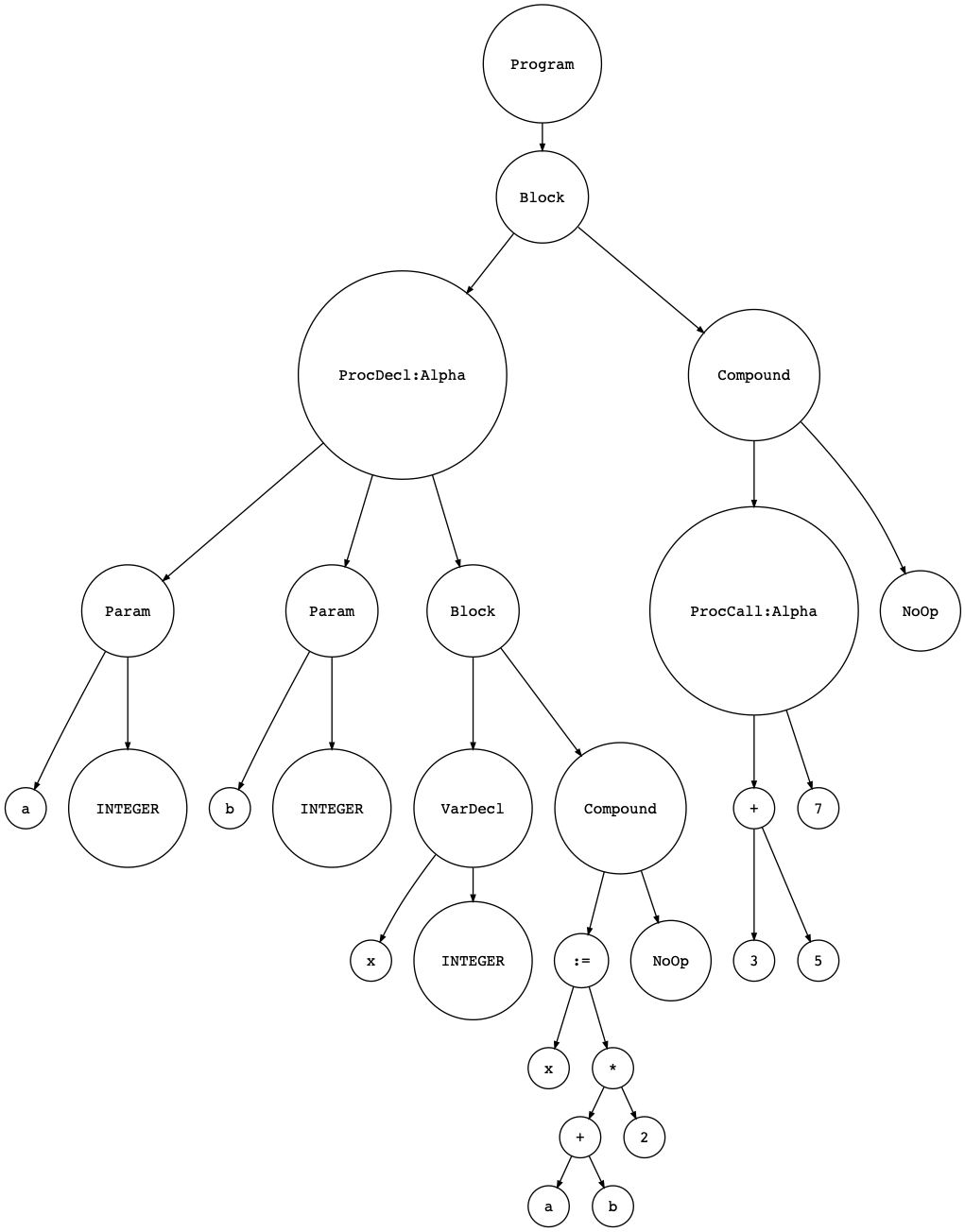
Так лучше. На рисунке выше вы можете увидеть наш новый узел AST ProcCall с меткой ProcCall:Alpha для вызова процедуры Alpha(3 + 5, 7). Двумя дочерними элементами узла ProcCall:Alpha являются поддеревья для аргументов 3 + 5 и 7, переданных вызову процедуры Alpha(3 + 5, 7).
Итак, мы достигли нашей цели на сегодня: при обнаружении вызова процедуры парсер строит AST с узлом ProcCall для вызова процедуры, а семантический анализатор и интерпретатор не выдают никаких ошибок при обходе AST.
Теперь пришло время для упражнения.

Упражнение: Добавьте проверку в семантический анализатор, которая проверяет, что количество аргументов (фактических параметров), переданных вызову процедуры, равно количеству формальных параметров, определенных в соответствующем объявлении процедуры. Возьмем объявление процедуры Alpha, которое мы использовали ранее в статье, в качестве примера:
procedure Alpha(a : integer; b : integer);
var x : integer;
begin
x := (a + b ) * 2;
end;
Количество формальных параметров в объявлении процедуры выше равно двум (целые числа a и b). Ваша проверка должна выдавать ошибку, если вы попытаетесь вызвать процедуру с количеством аргументов, отличным от двух:
Alpha(); { 0 аргументов —> ОШИБКА }
Alpha(1); { 1 аргумент —> ОШИБКА }
Alpha(1, 2, 3); { 3 аргумента —> ОШИБКА }
Вы можете найти решение упражнения в файле solutions.txt на GitHub , но попробуйте разработать собственное решение, прежде чем заглядывать в файл.
На сегодня это все. В следующей статье мы начнем изучать, как интерпретировать вызовы процедур. Мы рассмотрим такие темы, как стек вызовов и записи активации. Это будет дикая поездка :) Так что следите за обновлениями и до встречи в следующий раз!
Resources used in preparation for this article (some links are affiliate links):

