

Материалы ОП
Вы пассивно изучали материал в этих статьях или активно практиковали его? Надеюсь, вы активно практиковали его. Я действительно на это надеюсь :)
Помните, что говорил Конфуций?
“Я слышу и забываю.”
“Я вижу и запоминаю.”
“Я делаю и понимаю.”
В предыдущей статье вы узнали, как разбирать (распознавать) и интерпретировать арифметические выражения с любым количеством операторов сложения или вычитания, например “7 - 3 + 2 - 1”. Вы также узнали о синтаксических диаграммах и о том, как их можно использовать для определения синтаксиса языка программирования.
Сегодня вы узнаете, как разбирать и интерпретировать арифметические выражения с любым количеством операторов умножения и деления, например “7 * 4 / 2 * 3”. Деление в этой статье будет целочисленным, поэтому, если выражение “9 / 4”, то ответом будет целое число: 2.
Я также сегодня довольно много расскажу о еще одном широко используемом обозначении для определения синтаксиса языка программирования. Оно называется контекстно-свободные грамматики (грамматики, сокращенно) или БНФ (Backus-Naur Form). Для целей этой статьи я не буду использовать чистую нотацию БНФ, а скорее модифицированную нотацию EBNF.
Вот несколько причин для использования грамматик:
Грамматика определяет синтаксис языка программирования в сжатой форме. В отличие от синтаксических диаграмм, грамматики очень компактны. Вы увидите, что я буду использовать грамматики все больше и больше в будущих статьях. Грамматика может служить отличной документацией. Грамматика - это хорошая отправная точка, даже если вы вручную пишете свой парсер с нуля. Довольно часто вы можете просто преобразовать грамматику в код, следуя набору простых правил. Существует набор инструментов, называемых генераторами парсеров, которые принимают грамматику в качестве входных данных и автоматически генерируют парсер для вас на основе этой грамматики. Я расскажу об этих инструментах позже в этой серии. Теперь давайте поговорим о механических аспектах грамматик, хорошо?
Вот грамматика, которая описывает арифметические выражения, такие как “7 * 4 / 2 * 3” (это всего лишь одно из многих выражений, которые могут быть сгенерированы грамматикой):
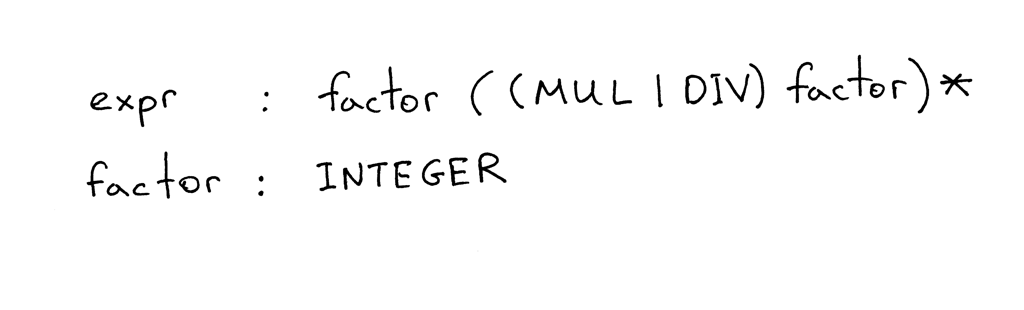
Грамматика состоит из последовательности правил, также известных как продукции. В нашей грамматике есть два правила:
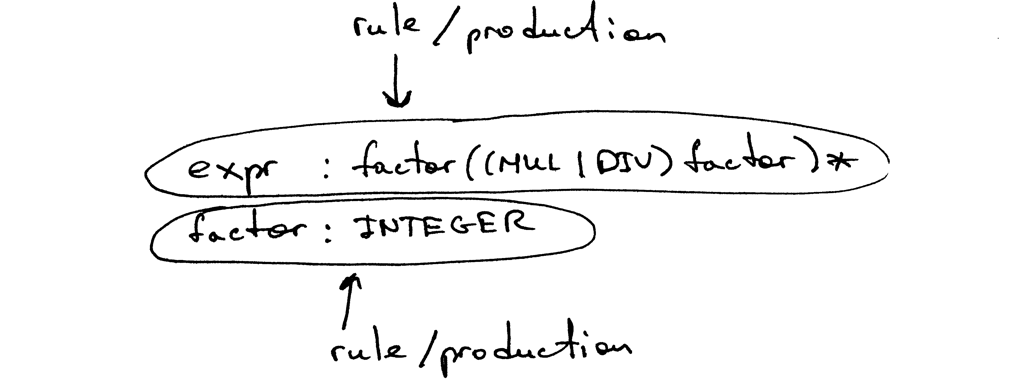
Правило состоит из нетерминала, называемого головой или левой частью продукции, двоеточия и последовательности терминалов и/или нетерминалов, называемых телом или правой частью продукции:
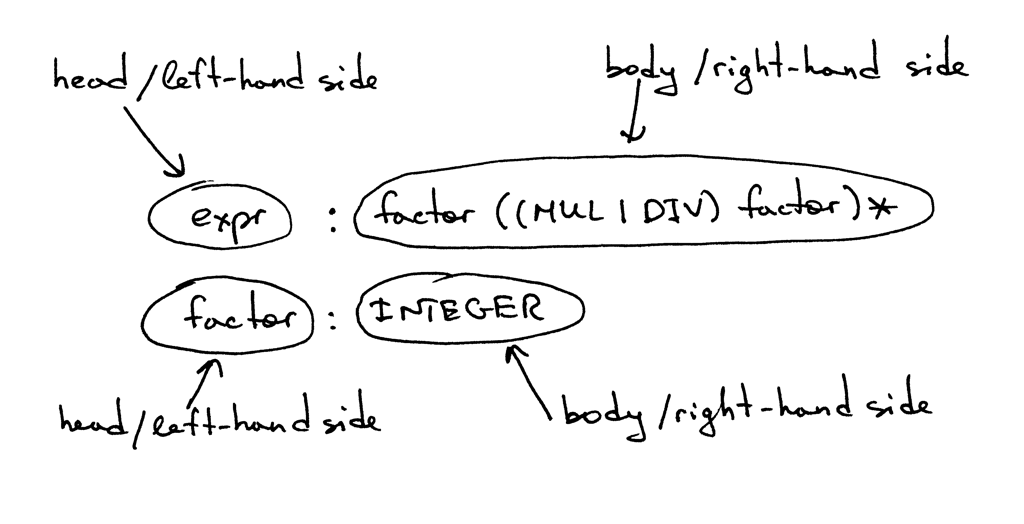
В грамматике, которую я показал выше, токены, такие как MUL, DIV и INTEGER, называются терминалами, а переменные, такие как expr и factor, называются нетерминалами. Нетерминалы обычно состоят из последовательности терминалов и/или нетерминалов:
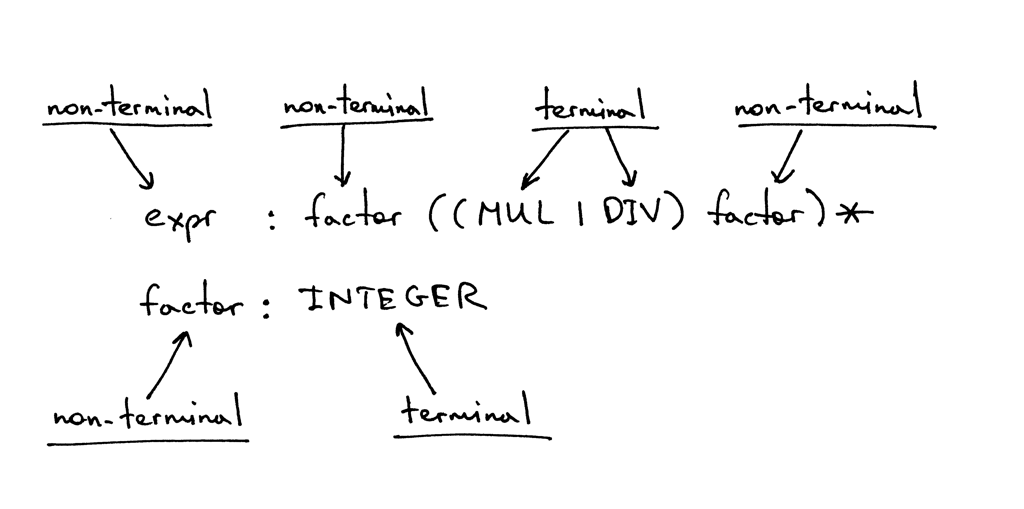
Нетерминальный символ в левой части первого правила называется начальным символом. В случае нашей грамматики начальным символом является expr:

Вы можете читать правило expr как “Expr может быть factor, за которым необязательно следует оператор умножения или деления, за которым следует другой factor, за которым, в свою очередь, необязательно следует оператор умножения или деления, за которым следует другой factor, и так далее и тому подобное”.
Что такое factor? Для целей этой статьи factor - это просто целое число.
Давайте быстро рассмотрим символы, используемые в грамматике, и их значение.
| - Альтернативы. Черта означает “или”. Так (MUL | DIV) означает либо MUL, либо DIV. ( … ) - Открывающая и закрывающая скобки означают группировку терминалов и/или нетерминалов, как в (MUL | DIV). ( … )* - Соответствие содержимому внутри группы ноль или более раз. Если вы работали с регулярными выражениями в прошлом, то символы |, () и (…)* должны быть вам довольно знакомы.
Грамматика определяет язык, объясняя, какие предложения он может формировать. Вот как вы можете вывести арифметическое выражение, используя грамматику: сначала вы начинаете с начального символа expr, а затем многократно заменяете нетерминал телом правила для этого нетерминала, пока не сгенерируете предложение, состоящее исключительно из терминалов. Эти предложения образуют язык, определяемый грамматикой.
Если грамматика не может вывести определенное арифметическое выражение, то она не поддерживает это выражение, и парсер сгенерирует синтаксическую ошибку, когда попытается распознать выражение.
Я думаю, что пара примеров не помешает. Вот как грамматика выводит выражение 3:

Вот как грамматика выводит выражение 3 * 7:

И вот как грамматика выводит выражение 3 * 7 / 2:

Ух ты, довольно много теории!
Я думаю, когда я впервые прочитал о грамматиках, связанной с ними терминологии и всем таком прочем, я почувствовал что-то вроде этого:

Я могу заверить вас, что я определенно не был таким:

Мне потребовалось некоторое время, чтобы освоиться с нотацией, тем, как она работает, и ее связью с парсерами и лексерами, но я должен сказать вам, что в долгосрочной перспективе стоит ее изучить, потому что она так широко используется на практике и в литературе по компиляторам, что вы обязательно столкнетесь с ней в какой-то момент. Так почему бы не раньше, чем позже? :)
Теперь давайте сопоставим эту грамматику с кодом, хорошо?
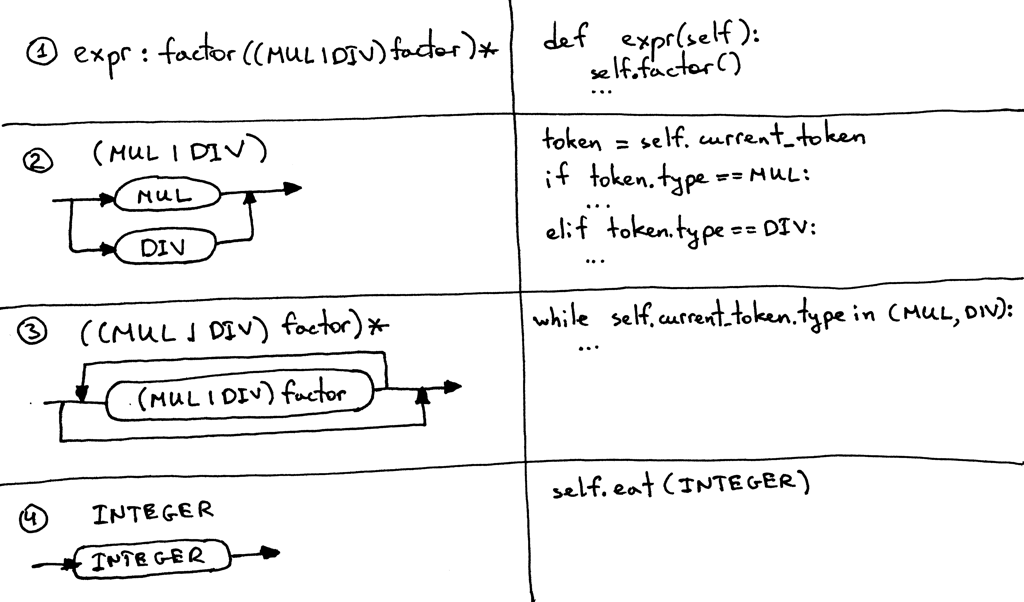
Вот рекомендации, которые мы будем использовать для преобразования грамматики в исходный код. Следуя им, вы можете буквально перевести грамматику в работающий парсер:
Каждое правило R, определенное в грамматике, становится методом с тем же именем, а ссылки на это правило становятся вызовом метода: R(). Тело метода следует потоку тела правила, используя те же самые рекомендации. Альтернативы (a1 | a2 | aN) становятся оператором if-elif-else Необязательная группировка (…)* становится оператором while, который может зацикливаться ноль или более раз Каждая ссылка на токен T становится вызовом метода eat: eat(T). Метод eat работает таким образом, что он потребляет токен T, если он соответствует текущему токену lookahead, затем он получает новый токен из лексера и присваивает этот токен внутренней переменной current_token. Визуально рекомендации выглядят так:
Давайте двигаться дальше и преобразуем нашу грамматику в код, следуя приведенным выше рекомендациям.
В нашей грамматике есть два правила: одно правило expr и одно правило factor. Давайте начнем с правила factor (продукции). Согласно рекомендациям, вам нужно создать метод с именем factor (рекомендация 1), который имеет один вызов метода eat для потребления токена INTEGER (рекомендация 4):
def factor(self):
self.eat(INTEGER)
Это было легко, не так ли?
Вперед!
Правило expr становится методом expr (опять же, согласно рекомендации 1). Тело правила начинается со ссылки на factor, которая становится вызовом метода factor(). Необязательная группировка (…)* становится циклом while, а альтернативы (MUL | DIV) становятся оператором if-elif-else. Объединив эти части вместе, мы получаем следующий метод expr:
def expr(self):
self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
self.factor()
elif token.type == DIV:
self.eat(DIV)
self.factor()
Пожалуйста, потратьте некоторое время и изучите, как я сопоставил грамматику с исходным кодом. Убедитесь, что вы понимаете эту часть, потому что она пригодится вам позже.
Для вашего удобства я поместил приведенный выше код в файл parser.py, который содержит лексер и парсер без интерпретатора. Вы можете скачать файл прямо с GitHub и поиграть с ним. В нем есть интерактивная подсказка, где вы можете вводить выражения и смотреть, являются ли они действительными: то есть, может ли парсер, построенный в соответствии с грамматикой, распознать выражения.
Вот пример сеанса, который я запустил на своем компьютере:
$ python parser.py
calc> 3
calc> 3 * 7
calc> 3 * 7 / 2
calc> 3 *
Traceback (most recent call last):
File "parser.py", line 155, in <module>
main()
File "parser.py", line 151, in main
parser.parse()
File "parser.py", line 136, in parse
self.expr()
File "parser.py", line 130, in expr
self.factor()
File "parser.py", line 114, in factor
self.eat(INTEGER)
File "parser.py", line 107, in eat
self.error()
File "parser.py", line 97, in error
raise Exception('Invalid syntax')
Exception: Invalid syntax
Попробуйте!
Я не мог не упомянуть снова синтаксические диаграммы. Вот как будет выглядеть синтаксическая диаграмма для того же правила expr:
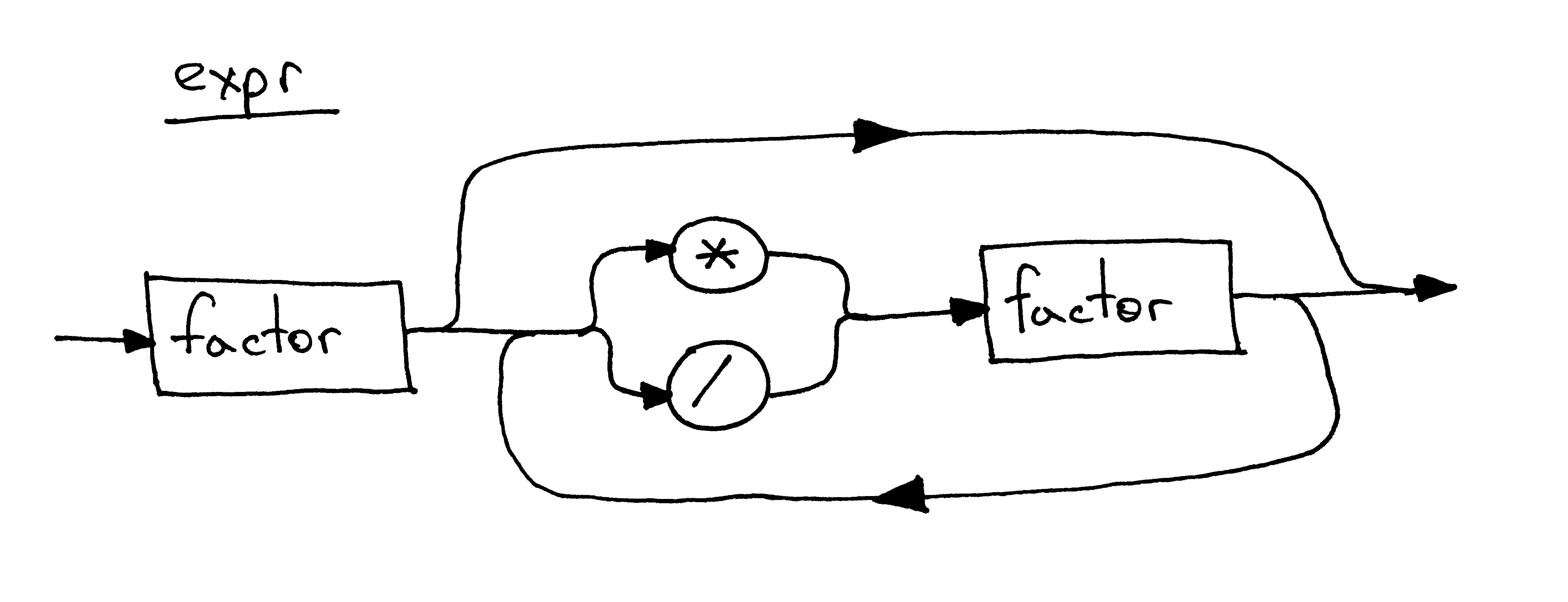
Пришло время углубиться в исходный код нашего нового интерпретатора арифметических выражений. Ниже приведен код калькулятора, который может обрабатывать допустимые арифметические выражения, содержащие целые числа и любое количество операторов умножения и деления (целочисленного деления). Вы также можете видеть, что я реорганизовал лексический анализатор в отдельный класс Lexer и обновил класс Interpreter, чтобы он принимал экземпляр Lexer в качестве параметра:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, MUL, DIV, EOF = 'INTEGER', 'MUL', 'DIV', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, MUL, DIV, or EOF
self.type = type
# token value: non-negative integer value, '*', '/', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "3 * 5", "12 / 3 * 4", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Invalid character')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
self.error()
return Token(EOF, None)
class Interpreter(object):
def __init__(self, lexer):
self.lexer = lexer
# set current token to the first token taken from the input
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
"""Return an INTEGER token value.
factor : INTEGER
"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter.
expr : factor ((MUL | DIV) factor)*
factor : INTEGER
"""
result = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
result = result * self.factor()
elif token.type == DIV:
self.eat(DIV)
result = result / self.factor()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
lexer = Lexer(text)
interpreter = Interpreter(lexer)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
Сохраните приведенный выше код в файл calc4.py или скачайте его прямо с GitHub. Как обычно, попробуйте и убедитесь сами, что он работает.
Вот пример сеанса, который я запустил на своем ноутбуке:
$ python calc4.py
calc> 7 * 4 / 2
14
calc> 7 * 4 / 2 * 3
42
calc> 10 * 4 * 2 * 3 / 8
30
Я знаю, вы не могли дождаться этой части :) Вот новые упражнения на сегодня:

Напишите грамматику, которая описывает арифметические выражения, содержащие любое количество операторов +, -, *, или /. С помощью грамматики вы должны иметь возможность выводить выражения, такие как “2 + 7 * 4”, “7 - 8 / 4”, “14 + 2 * 3 - 6 / 2” и так далее. Используя грамматику, напишите интерпретатор, который может вычислять арифметические выражения, содержащие любое количество операторов +, -, *, или /. Ваш интерпретатор должен уметь обрабатывать выражения, такие как “2 + 7 * 4”, “7 - 8 / 4”, “14 + 2 * 3 - 6 / 2” и так далее. Если вы закончили вышеуказанные упражнения, расслабьтесь и наслаждайтесь :)
Проверьте свое понимание.
Помня о грамматике из сегодняшней статьи, ответьте на следующие вопросы, обращаясь к рисунку ниже по мере необходимости:
Что такое контекстно-свободная грамматика (грамматика)? Сколько правил / продукций имеет грамматика? Что такое терминал? (Определите все терминалы на картинке) Что такое нетерминал? (Определите все нетерминалы на картинке) Что такое голова правила? (Определите все головы / левые части на картинке) Что такое тело правила? (Определите все тела / правые части на картинке) Что такое начальный символ грамматики?
Литература
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
- Modern Compiler Implementation in Java
- Modern Compiler Design
- Compilers: Principles, Techniques, and Tools (2nd Edition)