

Материалы ОП
Сегодня тот самый день :) “Почему?” - спросите вы. Причина в том, что сегодня мы завершаем наше обсуждение арифметических выражений (ну, почти), добавляя выражения в скобках в нашу грамматику и реализуя интерпретатор, который сможет вычислять выражения в скобках с произвольно глубокой вложенностью, такие как выражение 7 + 3 * (10 / (12 / (3 + 1) - 1)).
Давайте начнем, хорошо?
Во-первых, давайте изменим грамматику, чтобы поддерживать выражения внутри скобок. Как вы помните из Части 5, правило factor используется для основных единиц в выражениях. В той статье единственной основной единицей, которую мы имели, было целое число. Сегодня мы добавляем еще одну основную единицу - выражение в скобках. Давайте сделаем это.
Вот наша обновленная грамматика:
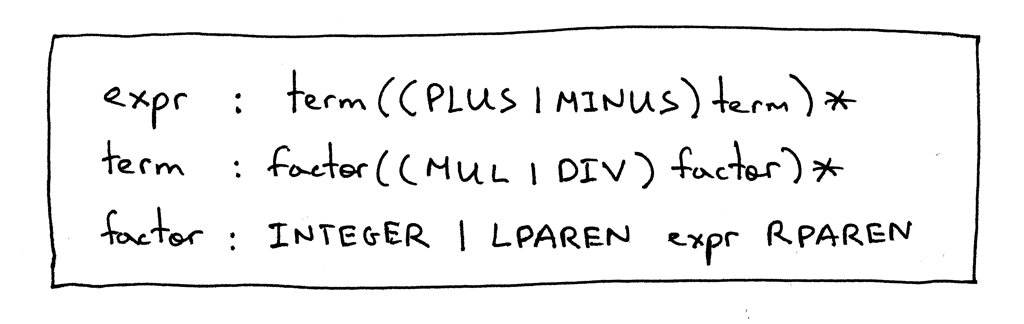
Продукции expr и term точно такие же, как и в Части 5, и единственное изменение заключается в продукции factor, где терминал LPAREN представляет собой левую скобку ‘(’, терминал RPAREN представляет собой правую скобку ‘)’, а нетерминал expr между скобками относится к правилу expr.
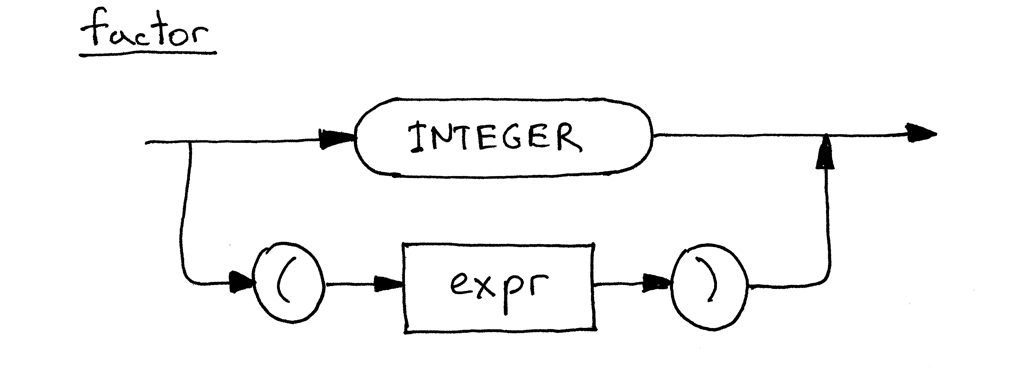
Вот обновленная синтаксическая диаграмма для factor, которая теперь включает альтернативы:
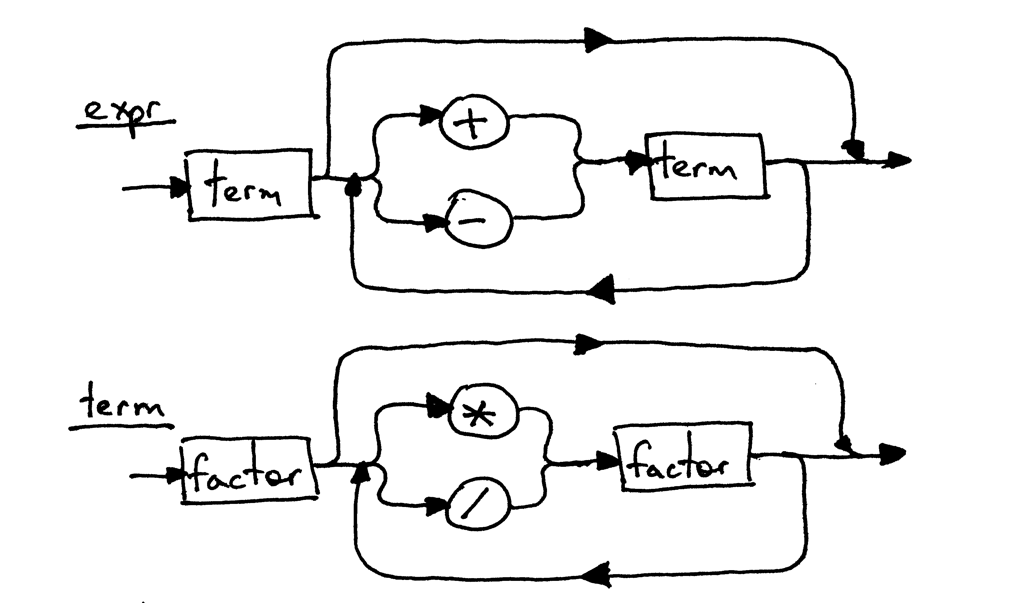
Поскольку грамматические правила для expr и term не изменились, их синтаксические диаграммы выглядят так же, как и в Части 5:
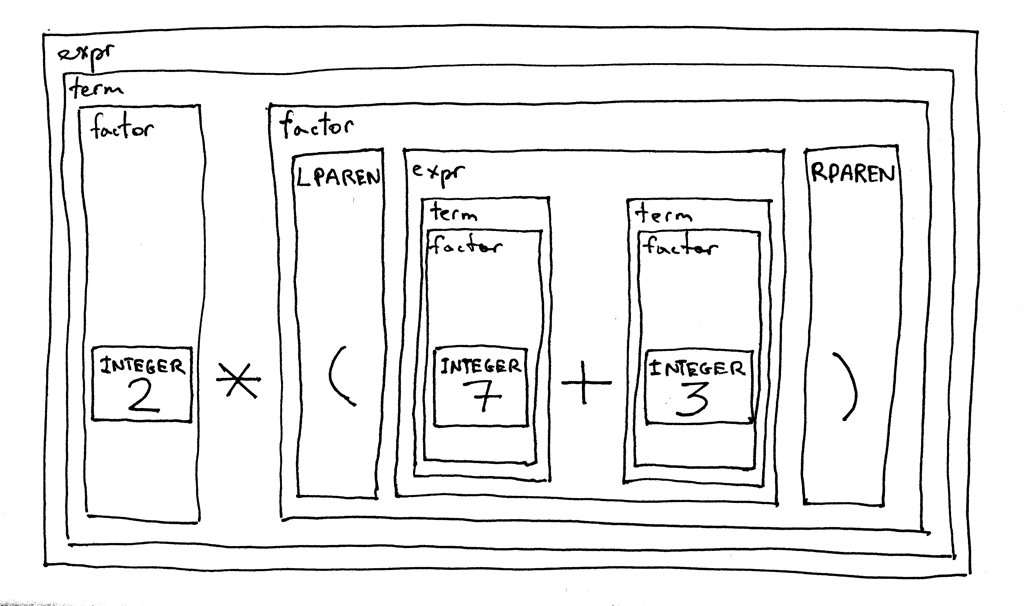
Вот интересная особенность нашей новой грамматики - она рекурсивна. Если вы попытаетесь вывести выражение 2 * (7 + 3), вы начнете со стартового символа expr и в конечном итоге дойдете до точки, где вы рекурсивно используете правило expr снова, чтобы вывести часть (7 + 3) исходного арифметического выражения.
Давайте разложим выражение 2 * (7 + 3) в соответствии с грамматикой и посмотрим, как это выглядит:
Небольшое отступление: если вам нужно освежить в памяти рекурсию, взгляните на книгу Дэниела П. Фридмана и Маттиаса Феллейзена “The Little Schemer” - она действительно хороша.
Хорошо, давайте двигаться дальше и переведем нашу новую обновленную грамматику в код.
Ниже приведены основные изменения в коде из предыдущей статьи:
Лексер был изменен, чтобы возвращать еще два токена: LPAREN для левой скобки и RPAREN для правой скобки. Метод factor интерпретатора был немного обновлен для разбора выражений в скобках в дополнение к целым числам. Вот полный код калькулятора, который может вычислять арифметические выражения, содержащие целые числа; любое количество операторов сложения, вычитания, умножения и деления; и выражения в скобках с произвольно глубокой вложенностью:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, PLUS, MINUS, MUL, DIV, LPAREN, RPAREN, EOF = (
'INTEGER', 'PLUS', 'MINUS', 'MUL', 'DIV', '(', ')', 'EOF'
)
class Token(object):
def __init__(self, type, value):
self.type = type
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(PLUS, '+')
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "4 + 2 * 3 - 6 / 2"
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Invalid character')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '+':
self.advance()
return Token(PLUS, '+')
if self.current_char == '-':
self.advance()
return Token(MINUS, '-')
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
if self.current_char == '(':
self.advance()
return Token(LPAREN, '(')
if self.current_char == ')':
self.advance()
return Token(RPAREN, ')')
self.error()
return Token(EOF, None)
class Interpreter(object):
def __init__(self, lexer):
self.lexer = lexer
# set current token to the first token taken from the input
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
"""factor : INTEGER | LPAREN expr RPAREN"""
token = self.current_token
if token.type == INTEGER:
self.eat(INTEGER)
return token.value
elif token.type == LPAREN:
self.eat(LPAREN)
result = self.expr()
self.eat(RPAREN)
return result
def term(self):
"""term : factor ((MUL | DIV) factor)*"""
result = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
result = result * self.factor()
elif token.type == DIV:
self.eat(DIV)
result = result / self.factor()
return result
def expr(self):
"""Arithmetic expression parser / interpreter.
calc> 7 + 3 * (10 / (12 / (3 + 1) - 1))
22
expr : term ((PLUS | MINUS) term)*
term : factor ((MUL | DIV) factor)*
factor : INTEGER | LPAREN expr RPAREN
"""
result = self.term()
while self.current_token.type in (PLUS, MINUS):
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
result = result + self.term()
elif token.type == MINUS:
self.eat(MINUS)
result = result - self.term()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
lexer = Lexer(text)
interpreter = Interpreter(lexer)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
Сохраните приведенный выше код в файл calc6.py, попробуйте его и убедитесь сами, что ваш новый интерпретатор правильно вычисляет арифметические выражения, содержащие различные операторы и скобки.
Вот пример сеанса:
$ python calc6.py
calc> 3
3
calc> 2 + 7 * 4
30
calc> 7 - 8 / 4
5
calc> 14 + 2 * 3 - 6 / 2
17
calc> 7 + 3 * (10 / (12 / (3 + 1) - 1))
22
calc> 7 + 3 * (10 / (12 / (3 + 1) - 1)) / (2 + 3) - 5 - 3 + (8)
10
calc> 7 + (((3 + 2)))
12
И вот новое упражнение для вас на сегодня:
Напишите свою собственную версию интерпретатора арифметических выражений, как описано в этой статье. Помните: повторение - мать учения.
Литература
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
- Modern Compiler Implementation in Java
- Modern Compiler Design
- Compilers: Principles, Techniques, and Tools (2nd Edition)