

Материалы ОП
Я помню, когда учился в университете (давным-давно) и изучал системное программирование, я считал, что единственные “настоящие” языки - это Assembly и C. А Pascal был - как бы это помягче сказать - очень высокоуровневым языком, используемым разработчиками приложений, которые не хотели знать, что происходит под капотом.
Тогда я и представить себе не мог, что буду писать почти все на Python (и любить каждую его частичку), чтобы оплачивать свои счета, и что я также буду писать интерпретатор и компилятор для Pascal по причинам, которые я указал в самой первой статье серии.
В наши дни я считаю себя энтузиастом языков программирования, и меня восхищают все языки и их уникальные особенности. Сказав это, я должен отметить, что мне нравится использовать одни языки гораздо больше, чем другие. Я предвзят, и я первый это признаю. :)
Это я до:
А это сейчас:
Ладно, давайте перейдем к делу. Вот что вы узнаете сегодня:
- Как разбирать и интерпретировать определение программы на Pascal.
- Как разбирать и интерпретировать составные операторы.
- Как разбирать и интерпретировать операторы присваивания, включая переменные.
- Немного о таблицах символов и о том, как хранить и искать переменные.
Я буду использовать следующий пример программы, похожей на Pascal, чтобы представить новые концепции:
BEGIN
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number / 4;
c := a - - b
END;
x := 11;
END.
Вы можете сказать, что это довольно большой скачок от интерпретатора командной строки, который вы написали до сих пор, следуя предыдущим статьям серии, но это скачок, который, я надеюсь, принесет волнение. Это уже не “просто” калькулятор, мы здесь серьезно, по-паскалевски. :)
Давайте углубимся и посмотрим на синтаксические диаграммы для новых языковых конструкций и соответствующие им грамматические правила.
На старт: Внимание. Марш!
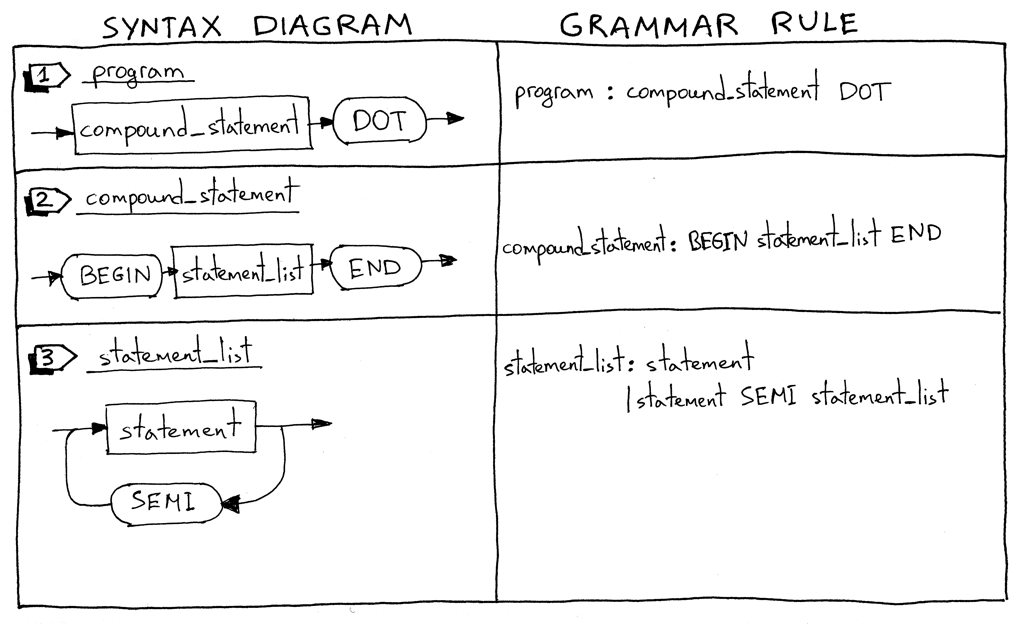
Я начну с описания того, что такое программа на Pascal. Программа на Pascal состоит из составного оператора, который заканчивается точкой. Вот пример программы:
"BEGIN END."
Я должен отметить, что это не полное определение программы, и мы расширим его позже в серии.
Что такое составной оператор? Составной оператор - это блок, отмеченный BEGIN и END, который может содержать список (возможно, пустой) операторов, включая другие составные операторы. Каждый оператор внутри составного оператора, за исключением последнего, должен заканчиваться точкой с запятой. Последний оператор в блоке может иметь или не иметь завершающую точку с запятой. Вот несколько примеров допустимых составных операторов:
"BEGIN END"
"BEGIN a := 5; x := 11 END"
"BEGIN a := 5; x := 11; END"
"BEGIN BEGIN a := 5 END; x := 11 END"
Список операторов - это список из нуля или более операторов внутри составного оператора. См. выше несколько примеров.
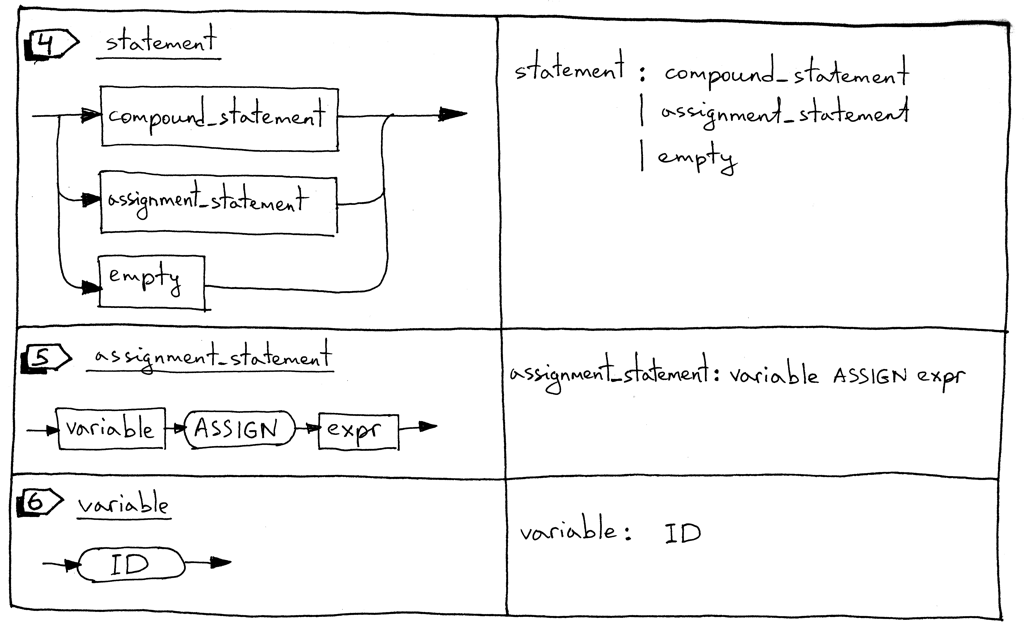
Оператор может быть составным оператором, оператором присваивания или пустым оператором.
Оператор присваивания - это переменная, за которой следует токен ASSIGN (два символа, ‘:’ и ‘=’), за которым следует выражение.
"a := 11"
"b := a + 9 - 5 * 2"
Переменная - это идентификатор. Мы будем использовать токен ID для переменных. Значением токена будет имя переменной, например, ‘a’, ’number’ и т.д. В следующем блоке кода ‘a’ и ‘b’ являются переменными:
"BEGIN a := 11; b := a + 9 - 5 * 2 END"
Пустой оператор представляет собой грамматическое правило без дальнейших продукций. Мы используем грамматическое правило empty_statement, чтобы указать конец statement_list в парсере, а также чтобы разрешить пустые составные операторы, как в ‘BEGIN END’.
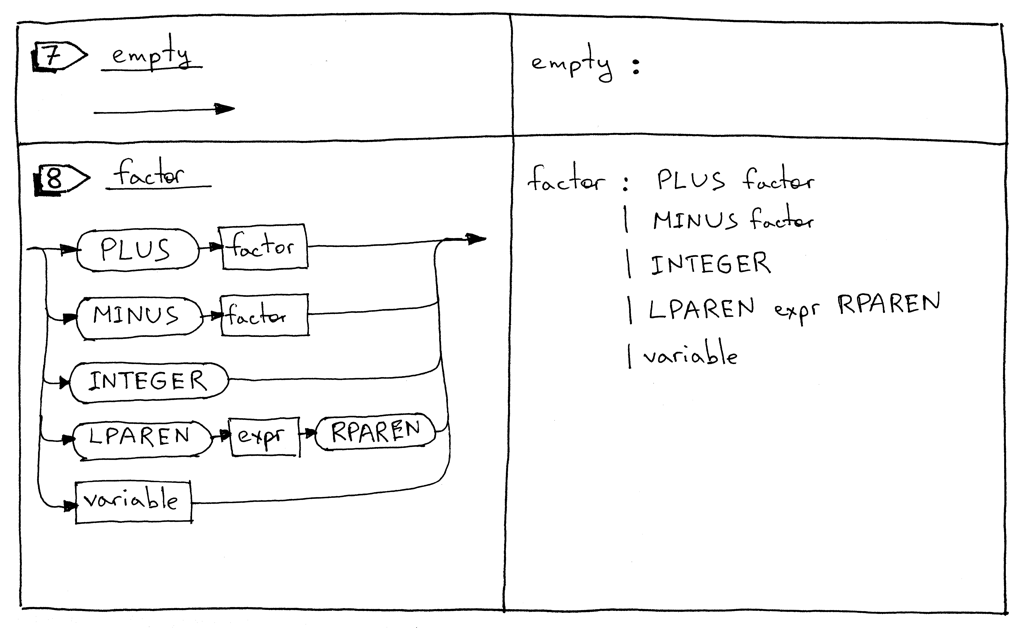
Правило factor обновлено для обработки переменных.
Теперь давайте посмотрим на нашу полную грамматику:
program : compound_statement DOT
compound_statement : BEGIN statement_list END
statement_list : statement
| statement SEMI statement_list
statement : compound_statement
| assignment_statement
| empty
assignment_statement : variable ASSIGN expr
empty :
expr: term ((PLUS | MINUS) term)*
term: factor ((MUL | DIV) factor)*
factor : PLUS factor
| MINUS factor
| INTEGER
| LPAREN expr RPAREN
| variable
variable: ID
Вы, вероятно, заметили, что я не использовал символ звездочки ‘*’ в правиле compound_statement для представления нуля или более повторений, а вместо этого явно указал правило statement_list. Это еще один способ представить операцию “ноль или более”, и он пригодится, когда мы будем рассматривать генераторы парсеров, такие как PLY, позже в серии. Я также разделил подправило “(PLUS | MINUS) factor” на два отдельных правила.
Чтобы поддержать обновленную грамматику, нам нужно внести ряд изменений в наш лексер, парсер и интерпретатор. Давайте рассмотрим эти изменения одно за другим.
Вот краткое изложение изменений в нашем лексере:
Чтобы поддержать определение программы на Pascal, составные операторы, операторы присваивания и переменные, наш лексер должен возвращать новые токены:
- BEGIN (чтобы отметить начало составного оператора)
- END (чтобы отметить конец составного оператора)
- DOT (токен для символа точки ‘.’ , требуемый определением программы на Pascal)
- ASSIGN (токен для последовательности из двух символов ‘:=’). В Pascal оператор присваивания отличается от многих других языков, таких как C, Python, Java, Rust или Go, где вы использовали бы один символ ‘=’ для обозначения присваивания
- SEMI (токен для символа точки с запятой ‘;’ , который используется для отметки конца оператора внутри составного оператора)
- ID (токен для допустимого идентификатора. Идентификаторы начинаются с алфавитного символа, за которым следует любое количество буквенно-цифровых символов)
Иногда, чтобы иметь возможность различать разные токены, которые начинаются с одного и того же символа (’:’ vs ‘:=’ или ‘==’ vs ‘=>’), нам нужно заглянуть в буфер ввода, фактически не потребляя следующий символ. Для этой конкретной цели я ввел метод peek, который поможет нам токенизировать операторы присваивания. Этот метод не является строго обязательным, но я подумал, что представлю его раньше в серии, и это также сделает метод get_next_token немного чище. Все, что он делает, это возвращает следующий символ из текстового буфера, не увеличивая переменную self.pos. Вот сам метод:
def peek(self):
peek_pos = self.pos + 1
if peek_pos > len(self.text) - 1:
return None
else:
return self.text[peek_pos]
Поскольку переменные Pascal и зарезервированные ключевые слова являются идентификаторами, мы объединим их обработку в один метод под названием _id. Работает это так: лексер потребляет последовательность буквенно-цифровых символов, а затем проверяет, является ли эта последовательность зарезервированным словом. Если это так, он возвращает предварительно сконструированный токен для этого зарезервированного ключевого слова. А если это не зарезервированное ключевое слово, он возвращает новый токен ID, значением которого является строка символов (лексема). Готов поспорить, в этот момент вы думаете: “Боже, просто покажи мне код”. :) Вот он:
RESERVED_KEYWORDS = {
'BEGIN': Token('BEGIN', 'BEGIN'),
'END': Token('END', 'END'),
}
def _id(self):
"""Handle identifiers and reserved keywords"""
result = ''
while self.current_char is not None and self.current_char.isalnum():
result += self.current_char
self.advance()
token = RESERVED_KEYWORDS.get(result, Token(ID, result))
return token
А теперь давайте посмотрим на изменения в основном методе лексера get_next_token:
def get_next_token(self):
while self.current_char is not None:
...
if self.current_char.isalpha():
return self._id()
if self.current_char == ':' and self.peek() == '=':
self.advance()
self.advance()
return Token(ASSIGN, ':=')
if self.current_char == ';':
self.advance()
return Token(SEMI, ';')
if self.current_char == '.':
self.advance()
return Token(DOT, '.')
...
Пришло время увидеть наш блестящий новый лексер во всей красе и действии. Загрузите исходный код с GitHub и запустите свою оболочку Python из того же каталога, где вы сохранили файл spi.py:
>>> from spi import Lexer
>>> lexer = Lexer('BEGIN a := 2; END.')
>>> lexer.get_next_token()
Token(BEGIN, 'BEGIN')
>>> lexer.get_next_token()
Token(ID, 'a')
>>> lexer.get_next_token()
Token(ASSIGN, ':=')
>>> lexer.get_next_token()
Token(INTEGER, 2)
>>> lexer.get_next_token()
Token(SEMI, ';')
>>> lexer.get_next_token()
Token(END, 'END')
>>> lexer.get_next_token()
Token(DOT, '.')
>>> lexer.get_next_token()
Token(EOF, None)
>>>
Переходим к изменениям парсера.
Вот краткое изложение изменений в нашем парсере:
Начнем с новых AST-узлов:
- Compound AST-узел представляет собой составной оператор. Он содержит список узлов операторов в своей переменной children.
class Compound(AST):
"""Represents a 'BEGIN ... END' block"""
def __init__(self):
self.children = []
- Assign AST-узел представляет собой оператор присваивания. Его левая переменная предназначена для хранения узла Var, а его правая переменная - для хранения узла, возвращаемого методом парсера expr:
class Assign(AST):
def __init__(self, left, op, right):
self.left = left
self.token = self.op = op
self.right = right
- Var AST-узел (вы угадали) представляет собой переменную. self.value содержит имя переменной.
class Var(AST):
"""The Var node is constructed out of ID token."""
def __init__(self, token):
self.token = token
self.value = token.value
- NoOp-узел используется для представления пустого оператора. Например, ‘BEGIN END’ - это допустимый составной оператор, который не имеет операторов.
class NoOp(AST):
pass
Как вы помните, каждое правило из грамматики имеет соответствующий метод в нашем рекурсивном парсере. На этот раз мы добавляем семь новых методов. Эти методы отвечают за разбор новых языковых конструкций и построение новых AST-узлов. Они довольно просты:
def program(self):
"""program : compound_statement DOT"""
node = self.compound_statement()
self.eat(DOT)
return node
def compound_statement(self):
"""
compound_statement: BEGIN statement_list END
"""
self.eat(BEGIN)
nodes = self.statement_list()
self.eat(END)
root = Compound()
for node in nodes:
root.children.append(node)
return root
def statement_list(self):
"""
statement_list : statement
| statement SEMI statement_list
"""
node = self.statement()
results = [node]
while self.current_token.type == SEMI:
self.eat(SEMI)
results.append(self.statement())
if self.current_token.type == ID:
self.error()
return results
def statement(self):
"""
statement : compound_statement
| assignment_statement
| empty
"""
if self.current_token.type == BEGIN:
node = self.compound_statement()
elif self.current_token.type == ID:
node = self.assignment_statement()
else:
node = self.empty()
return node
def assignment_statement(self):
"""
assignment_statement : variable ASSIGN expr
"""
left = self.variable()
token = self.current_token
self.eat(ASSIGN)
right = self.expr()
node = Assign(left, token, right)
return node
def variable(self):
"""
variable : ID
"""
node = Var(self.current_token)
self.eat(ID)
return node
def empty(self):
"""An empty production"""
return NoOp()
Нам также необходимо обновить существующий метод factor для разбора переменных:
def factor(self):
"""factor : PLUS factor
| MINUS factor
| INTEGER
| LPAREN expr RPAREN
| variable
"""
token = self.current_token
if token.type == PLUS:
self.eat(PLUS)
node = UnaryOp(token, self.factor())
return node
...
else:
node = self.variable()
return node
Метод парсера parse обновлен для запуска процесса разбора путем разбора определения программы:
def parse(self):
node = self.program()
if self.current_token.type != EOF:
self.error()
return node
Вот наша примерная программа еще раз:
BEGIN
BEGIN
number := 2;
a := number;
b := 10 * a + 10 * number / 4;
c := a - - b
END;
x := 11;
END.
Давайте визуализируем это с помощью genastdot.py (Для краткости, при отображении узла Var он просто показывает имя переменной узла, а при отображении узла Assign он показывает ‘:=’ вместо текста ‘Assign’):
$ python genastdot.py assignments.txt > ast.dot && dot -Tpng -o ast.png ast.dot
И, наконец, вот необходимые изменения интерпретатора:
Чтобы интерпретировать новые AST-узлы, нам нужно добавить соответствующие методы-посетители в интерпретатор. Есть четыре новых метода-посетителя:
- visit_Compound
- visit_Assign
- visit_Var
- visit_NoOp
Методы-посетители Compound и NoOp довольно просты. Метод visit_Compound перебирает своих потомков и посещает каждого по очереди, а метод visit_NoOp ничего не делает.
def visit_Compound(self, node):
for child in node.children:
self.visit(child)
def visit_NoOp(self, node):
pass
Методы-посетители Assign и Var заслуживают более пристального рассмотрения.
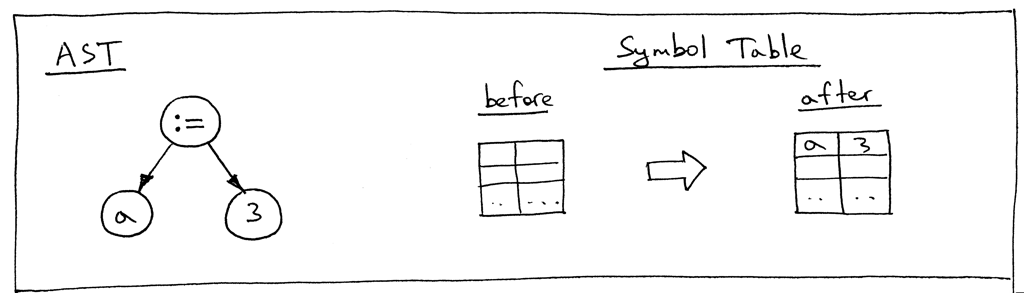
Когда мы присваиваем значение переменной, нам нужно где-то сохранить это значение, когда оно нам понадобится позже, и именно это делает метод visit_Assign:
def visit_Assign(self, node):
var_name = node.left.value
self.GLOBAL_SCOPE[var_name] = self.visit(node.right)
Метод сохраняет пару ключ-значение (имя переменной и значение, связанное с переменной) в таблице символов GLOBAL_SCOPE. Что такое таблица символов? Таблица символов - это абстрактный тип данных (ADT) для отслеживания различных символов в исходном коде. Единственная категория символов, которая у нас есть сейчас, - это переменные, и мы используем словарь Python для реализации ADT таблицы символов. Пока я просто скажу, что способ использования таблицы символов в этой статье довольно “хакерский”: это не отдельный класс со специальными методами, а простой словарь Python, и он также выполняет двойную функцию в качестве пространства памяти. В будущих статьях я буду говорить о таблицах символов гораздо подробнее, и вместе мы также удалим все хаки.
Давайте посмотрим на AST для оператора “a := 3;” и таблицу символов до и после того, как метод visit_Assign выполнит свою работу:
Теперь давайте посмотрим на AST для оператора “b := a + 7;”:
Как видите, правая часть оператора присваивания - “a + 7” - ссылается на переменную ‘a’, поэтому, прежде чем мы сможем вычислить выражение “a + 7”, нам нужно выяснить, какое значение имеет ‘a’, и это ответственность метода visit_Var:
def visit_Var(self, node):
var_name = node.value
val = self.GLOBAL_SCOPE.get(var_name)
if val is None:
raise NameError(repr(var_name))
else:
return val
Когда метод посещает узел Var, как на приведенном выше рисунке AST, он сначала получает имя переменной, а затем использует это имя в качестве ключа в словаре GLOBAL_SCOPE, чтобы получить значение переменной. Если он может найти значение, он возвращает его, если нет - он вызывает исключение NameError. Вот содержимое таблицы символов перед вычислением оператора присваивания “b := a + 7;”:
Это все изменения, которые нам нужно сделать сегодня, чтобы наш интерпретатор заработал. В конце основной программы мы просто выводим содержимое таблицы символов GLOBAL_SCOPE в стандартный вывод.
Давайте протестируем наш обновленный интерпретатор как из интерактивной оболочки Python, так и из командной строки. Убедитесь, что вы загрузили как исходный код для интерпретатора, так и файл assignments.txt перед тестированием:
Запустите свою оболочку Python:
$ python
>>> from spi import Lexer, Parser, Interpreter
>>> text = """\
... BEGIN
...
... BEGIN
... number := 2;
... a := number;
... b := 10 * a + 10 * number / 4;
... c := a - - b
... END;
...
... x := 11;
... END.
... """
>>> lexer = Lexer(text)
>>> parser = Parser(lexer)
>>> interpreter = Interpreter(parser)
>>> interpreter.interpret()
>>> print(interpreter.GLOBAL_SCOPE)
{'a': 2, 'x': 11, 'c': 27, 'b': 25, 'number': 2}
И из командной строки, используя исходный файл в качестве входных данных для нашего интерпретатора:
$ python spi.py assignments.txt
{'a': 2, 'x': 11, 'c': 27, 'b': 25, 'number': 2}
Если вы еще не пробовали, попробуйте сейчас и убедитесь сами, что интерпретатор выполняет свою работу должным образом.
Давайте подытожим, что вам нужно было сделать, чтобы расширить интерпретатор Pascal в этой статье:
- Добавить новые правила в грамматику
- Добавить новые токены и вспомогательные методы в лексер и обновить метод get_next_token
- Добавить новые AST-узлы в парсер для новых языковых конструкций
- Добавить новые методы, соответствующие новым грамматическим правилам, в наш рекурсивный парсер и обновить любые существующие методы, если необходимо (метод factor, я смотрю на вас. :)
- Добавить новые методы-посетители в интерпретатор
- Добавить словарь для хранения переменных и для их поиска
В этой части мне пришлось ввести ряд “хаков”, которые мы удалим по мере продвижения по серии:
- Правило грамматики программы неполное. Мы расширим его позже дополнительными элементами.
- Pascal - это язык со статической типизацией, и вы должны объявить переменную и ее тип перед ее использованием. Но, как вы видели, в этой статье это было не так.
- Пока нет проверки типов. Это не имеет большого значения на данном этапе, но я просто хотел упомянуть об этом явно. Как только мы добавим больше типов в наш интерпретатор, нам нужно будет сообщать об ошибке, когда вы попытаетесь добавить строку и целое число, например.
- Таблица символов в этой части - это простой словарь Python, который выполняет двойную функцию в качестве пространства памяти. Не беспокойтесь: таблицы символов - настолько важная тема, что я посвящу им несколько статей. А пространство памяти (управление во время выполнения) - это отдельная тема.
- В нашем простом калькуляторе из предыдущих статей мы использовали символ косой черты ‘/’ для обозначения целочисленного деления. В Pascal, однако, вы должны использовать ключевое слово div, чтобы указать целочисленное деление (см. упражнение 1).
- Есть также один хак, который я ввел намеренно, чтобы вы могли исправить его в упражнении 2: в Pascal все зарезервированные ключевые слова и идентификаторы нечувствительны к регистру, но интерпретатор в этой статье рассматривает их как чувствительные к регистру.
Чтобы держать вас в форме, вот новые упражнения для вас:
- Переменные Pascal и зарезервированные ключевые слова нечувствительны к регистру, в отличие от многих других языков программирования, поэтому BEGIN, begin и BeGin - все они относятся к одному и тому же зарезервированному ключевому слову. Обновите интерпретатор, чтобы переменные и зарезервированные ключевые слова не были чувствительны к регистру. Используйте следующую программу для ее тестирования:
BEGIN
BEGIN
number := 2;
a := NumBer;
B := 10 * a + 10 * NUMBER / 4;
c := a - - b
end;
x := 11;
END.
Я упоминал в разделе “хаки” ранее, что наш интерпретатор использует символ косой черты ‘/’ для обозначения целочисленного деления, но вместо этого он должен использовать зарезервированное ключевое слово Pascal div для целочисленного деления. Обновите интерпретатор, чтобы использовать ключевое слово div для целочисленного деления, тем самым устранив один из хаков.
Обновите интерпретатор, чтобы переменные также могли начинаться с подчеркивания, как в ‘_num := 5’.
На этом все на сегодня. Оставайтесь на связи и до скорой встречи.
Литература
- Language Implementation Patterns: Create Your Own Domain-Specific and General Programming Languages (Pragmatic Programmers)
- Writing Compilers and Interpreters: A Software Engineering Approach
- Modern Compiler Implementation in Java
- Modern Compiler Design
- Compilers: Principles, Techniques, and Tools (2nd Edition)