Лекция 6. Индексы
Определение
- Индексы — объекты базы данных, предназначенные для ускорения поиска и выборки строк из таблицы за счёт минимизации количества данных, которые нужно просматривать.
- Индексы также служат для поддержания некоторых ограничений целостности (например,
UNIQUE,PRIMARY KEY).
Как работает индекс?
Устанавливает соответствие между ключом (например, значением проиндексированного столбца) и строками таблицы, в которых этот ключ встречается. Строки идентифицируются с помощью TID (tuple id), который состоит из:
- номера блока файла;
- позиции строки внутри блока.
Увеличение затрат на запись
При любой операции над проиндексированными данными — будь то вставка, удаление или обновление строк таблицы — индексы, созданные для этой таблицы, должны быть перестроены, причём в рамках той же транзакции.
Платим записью ради ускорения чтения. Перебарщивать с индексами вредно — есть риск замедлить запись больше, чем выиграть на чтении.
Типы индексов в PostgreSQL
- B-tree
- Hash
- GIN
- GiST
- SP-GiST
- BRIN
Hash-индекс
- Поддерживает только поиск по равенству.
- По мере увеличения количества индексируемых строк одна из корзин расщепляется на две (динамическое хеширование).
- Элементы корзин упорядочены по хеш-кодам ключей, подходящие идентификаторы эффективно находятся двоичным поиском.
- До версии PostgreSQL 10 хеш-индексы не журналировались (не попадали в WAL), что делало их небезопасными при сбоях.
Ограничения
- Кластеризация таблицы по хеш-индексу не предусмотрена.
- Хеш-функция не сохраняет порядок — к хеш-индексу неприменимы свойства упорядоченности.
- Не может участвовать в сканировании только индекса (Index Only Scan): не сохраняет ключ индексации и требует перепроверки по таблице.
- Не работает с
NULL: операция «равно» не имеет смысла дляNULL. - Поиск значений из массива не реализован.
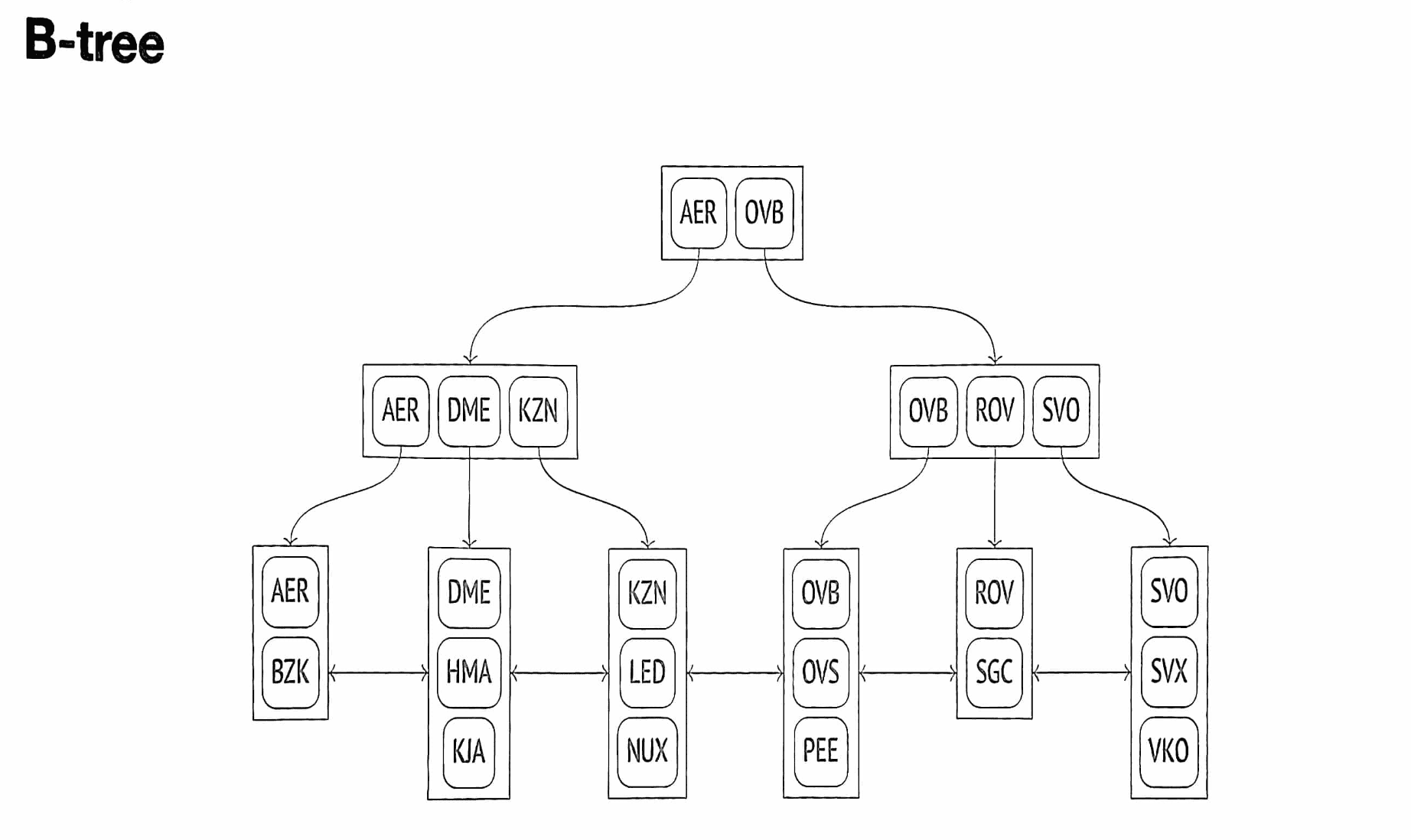
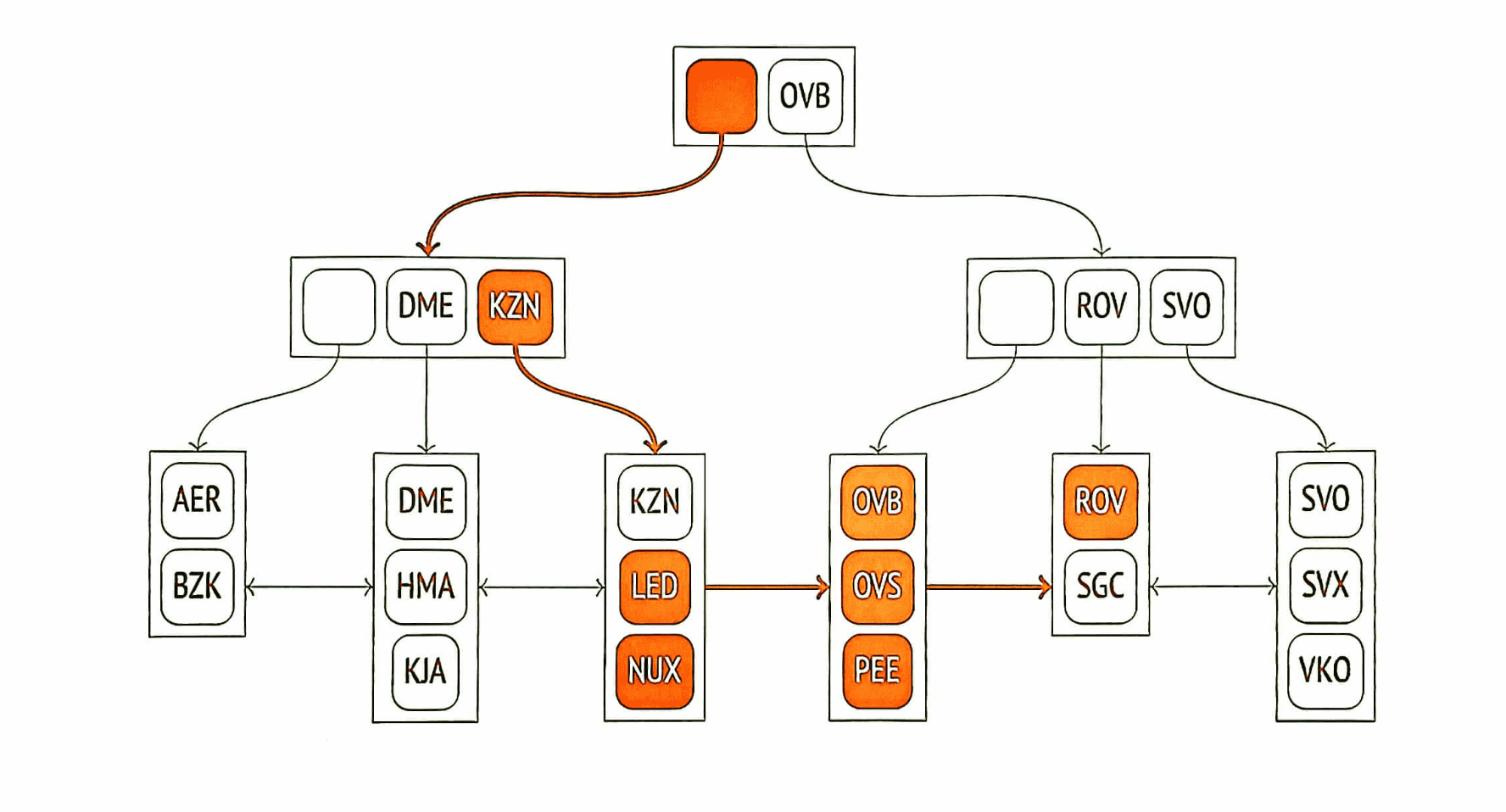
B-tree
Свойства
- Сбалансировано: все листья находятся на одной глубине. Поэтому поиск любого значения занимает одинаковое время.
- Сильно ветвисто: каждый узел содержит много элементов (часто сотни). За счёт этого глубина B-деревьев получается небольшой даже для очень больших таблиц.
- Упорядочено: данные в индексе отсортированы по возрастанию как между узлами, так и внутри каждого узла. Узлы одного уровня связаны двунаправленным списком.
Что поддерживает B-tree
- Поиск по равенству;
- Поиск по неравенству;
- Поиск по диапазону;
- Поиск по префиксу (для строк, например
LIKE 'abc%'); - Оптимизация сортировки (
ORDER BY); - Уникальность (
UNIQUE).
Особенности
- Дубликаты «схлопываются» в одну индексную запись, содержащую ключ и список табличных идентификаторов.
- Уникальные индексы могут содержать дубликаты ключей из-за многоверсионности (MVCC), поскольку индекс хранит ссылки на все версии табличных строк.
GiST (Generalized Search Tree)
GiST — не конкретный тип индекса, а фреймворк, который позволяет создавать пользовательские реализации для различных видов данных (геометрия, диапазоны, полнотекстовый поиск и др.).
R-дерево
- Идея R-дерева: плоскость разбивается на прямоугольники, которые в сумме покрывают все индексируемые точки.
- Индексная запись хранит ограничивающий прямоугольник, а предикат можно сформулировать так: точка лежит внутри данного ограничивающего прямоугольника.
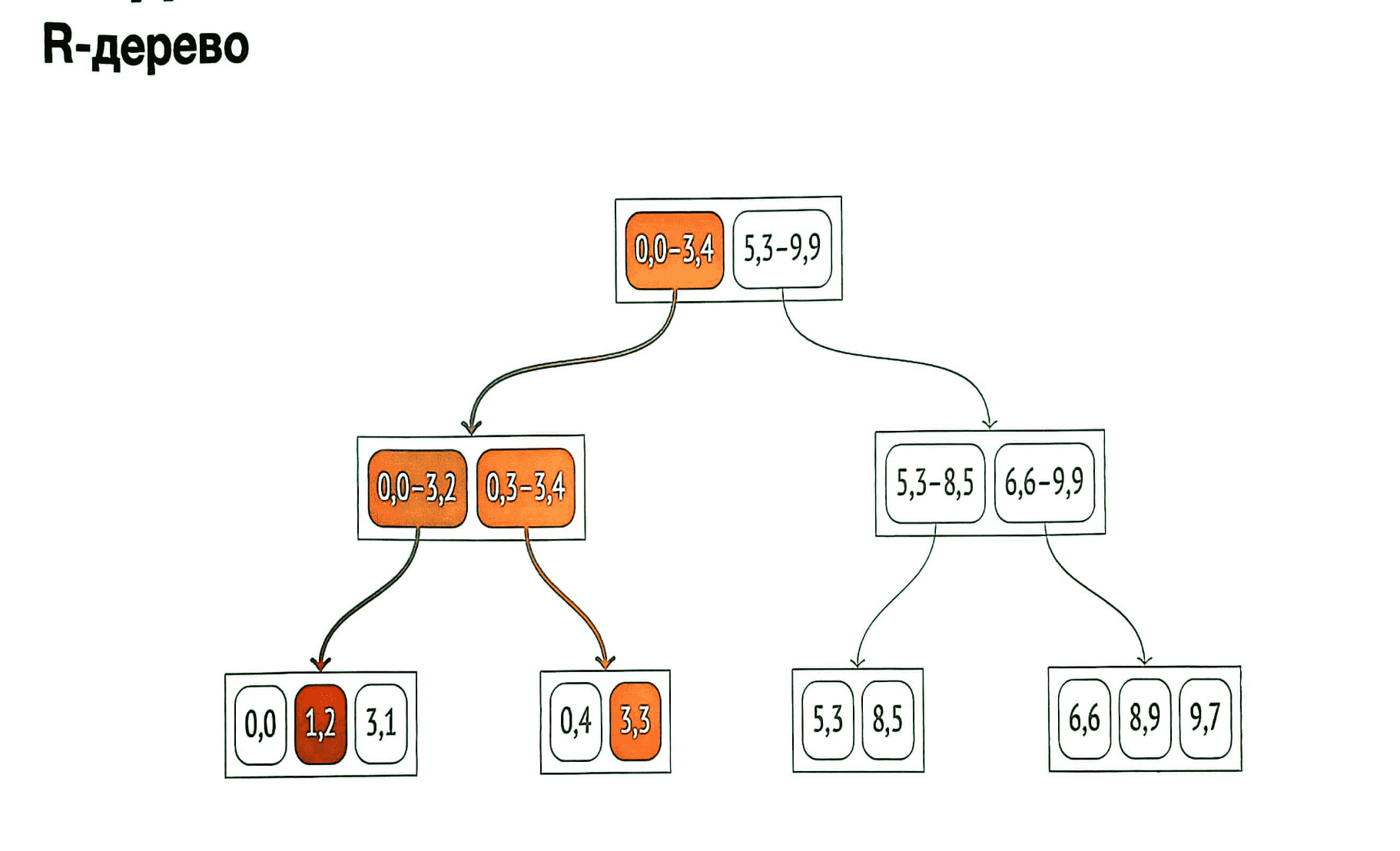
Типичный запрос, ускоряемый таким индексом, — получить все точки, входящие в заданную область.
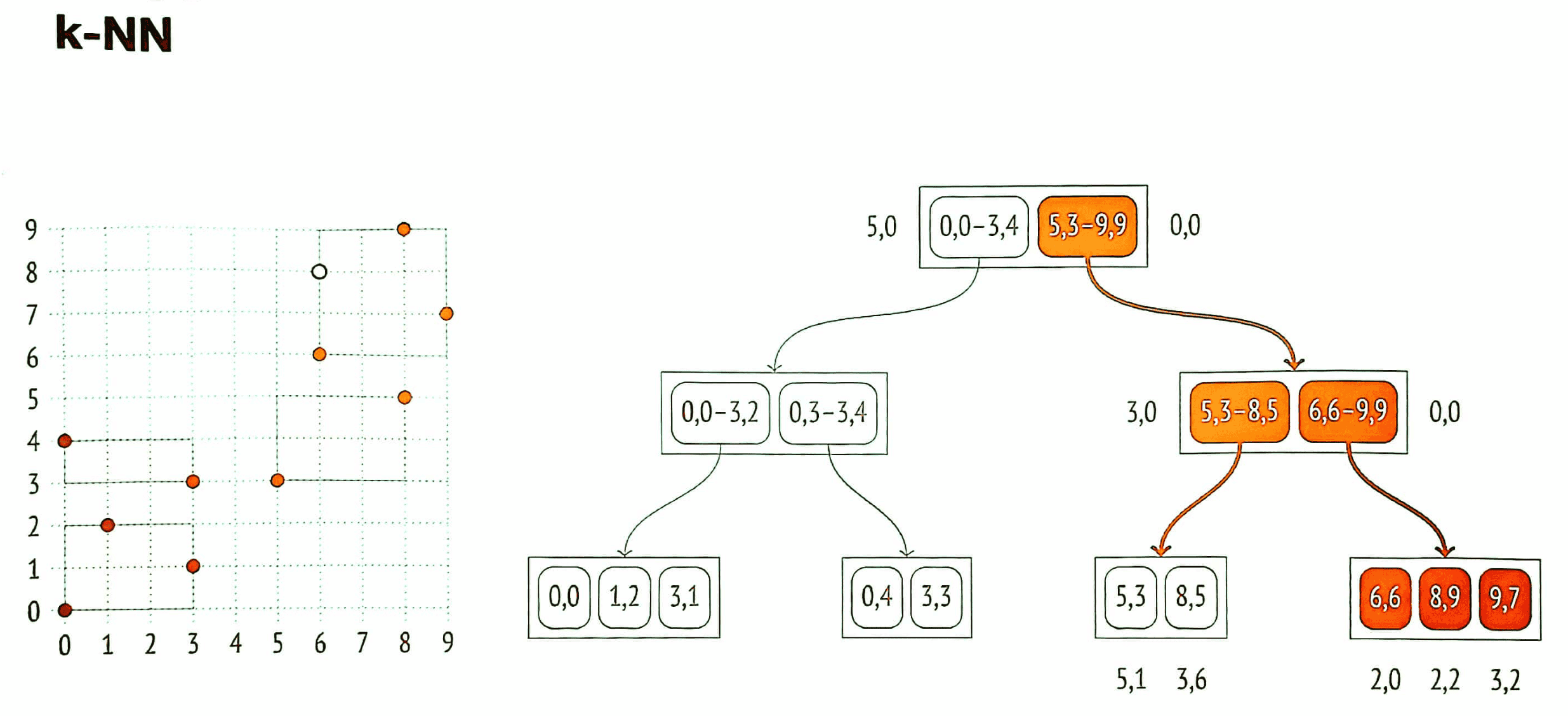
k-NN (k-Nearest Neighbors)
GiST позволяет эффективно искать $k$ ближайших соседей к заданной точке.
RD-дерево для полнотекстового поиска
- Задача: выбрать из набора документов те, которые соответствуют поисковому запросу.
- Для целей поиска документ приводится к специальному типу
tsvector, содержащему лексемы и их позиции в документе.
Полнотекстовый поиск
Чтобы полнотекстовый поиск работал быстро, его нужно поддержать индексом. Поскольку индексируются не сами документы, а значения tsvector, есть два варианта:
- построить индекс по выражению с приведением типа;
- создать отдельный столбец типа
tsvectorи индексировать его.
Идея RD-дерева
R-дерево как таковое не годится для индексации документов, поскольку к ним неприменимо понятие ограничивающего прямоугольника. Используется модификация — RD-дерево (Russian Doll, «матрёшка»).
Вместо ограничивающего прямоугольника это дерево использует ограничивающее множество, то есть множество, содержащее все элементы дочерних множеств.
Сигнатурное дерево
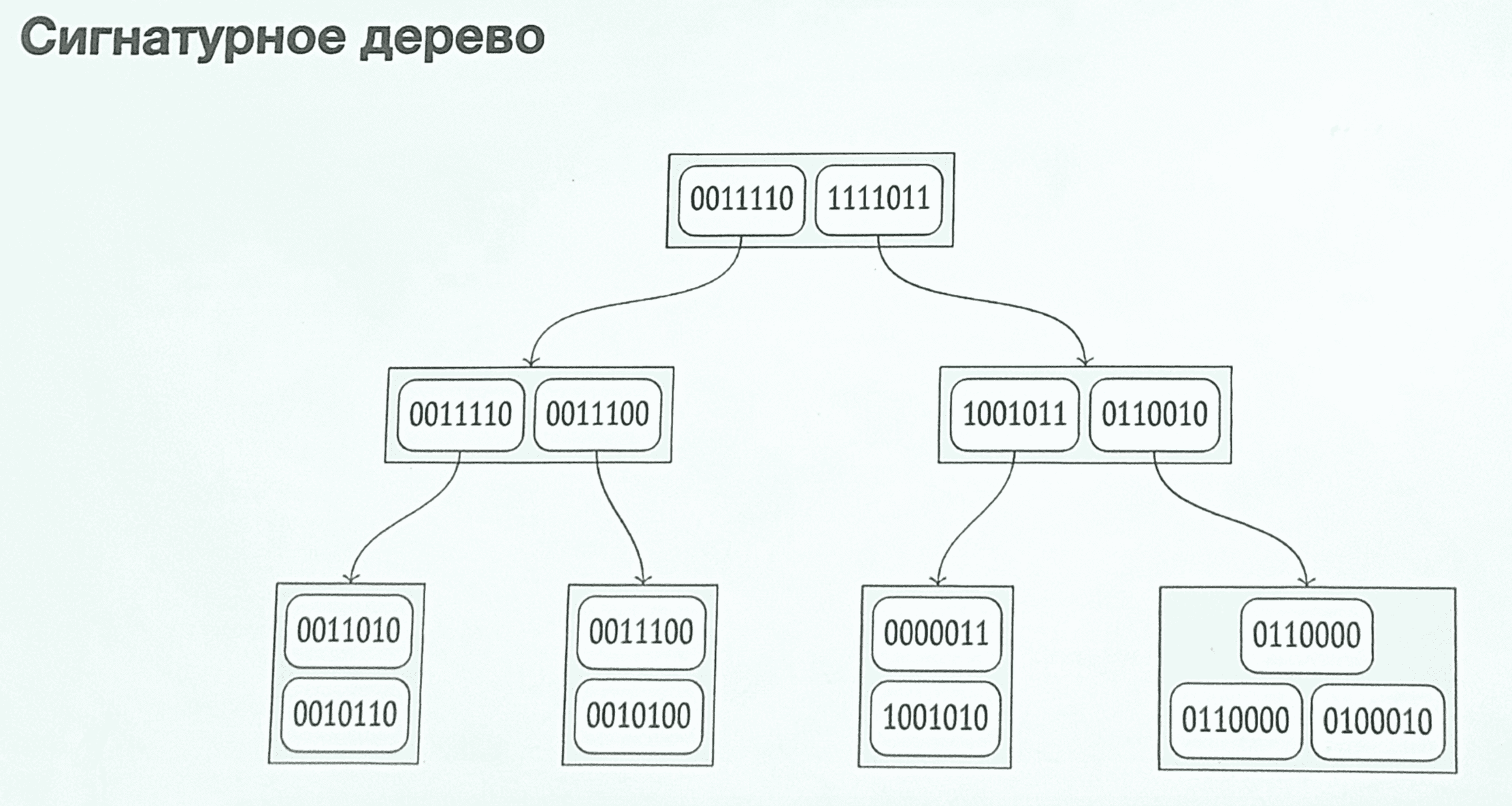
Используется фильтр Блума. Каждую лексему можно представить сигнатурой — битовой строкой определённой длины, в которой все биты равны нулю, кроме одного, который равен единице. Номер установленного бита определяется значением хеш-функции от лексемы.
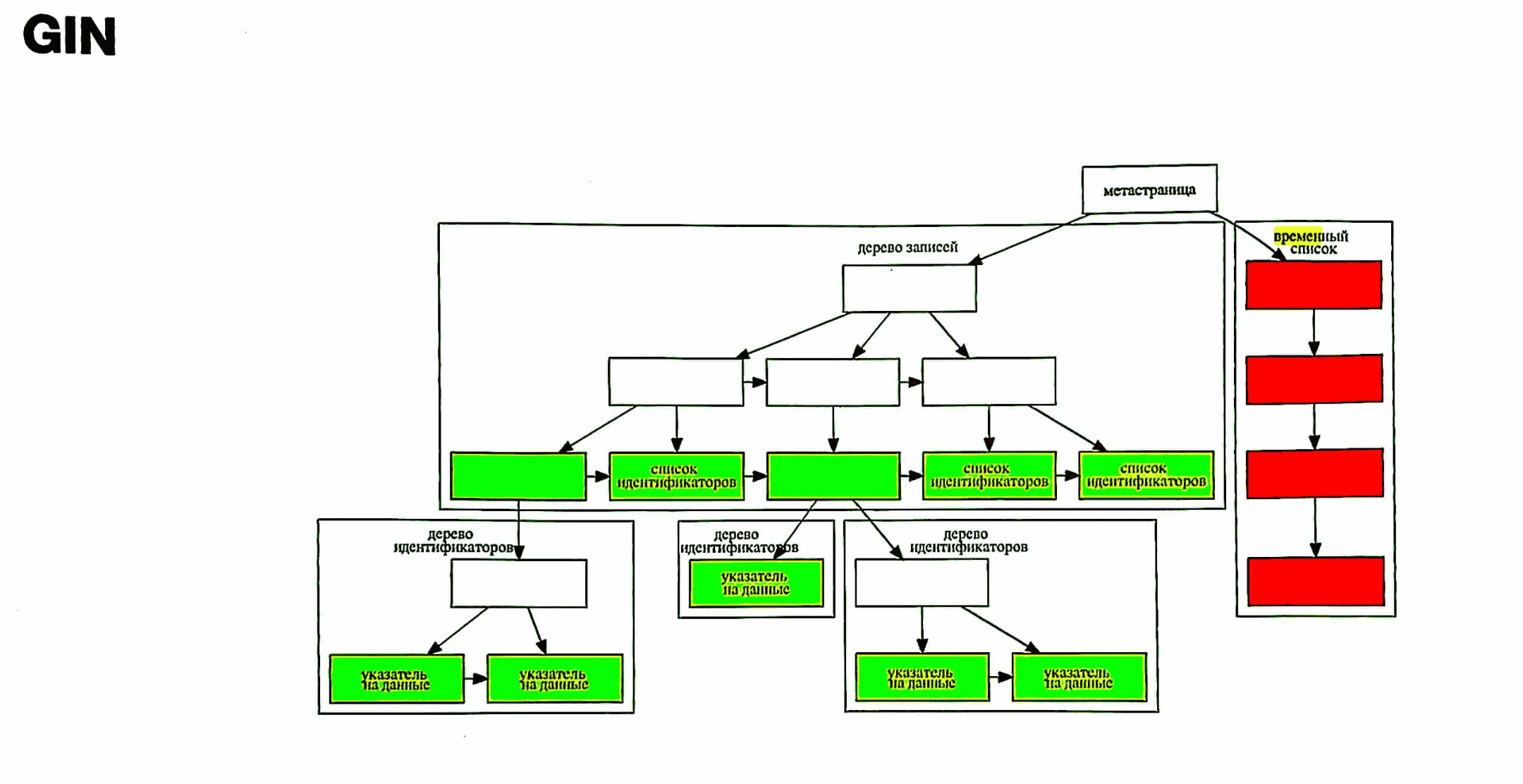
GIN (Generalized Inverted Index)
Аналогия
Предметный указатель в конце книги: собраны все важные термины, и для каждого приведён список страниц. Чтобы указателем было удобно пользоваться, он составляется по алфавиту. Так и GIN полагается на то, что элементы составных значений можно упорядочить, и в качестве основной структуры использует B-tree.
Назначение
Тип индексной структуры, предназначенной для работы с коллекциями данных и для быстрого поиска по составным структурам. Особенно эффективен, когда одно поле содержит множество значений (массивы, JSON, tsvector).