

Лекция 9. Этапы выполнения запроса
Лексический и синтаксический разбор
- Сервер принимает SQL-текст запроса и анализирует его на наличие синтаксических ошибок.
- Результат — дерево разбора (parse tree), представляющее структуру запроса.
Семантический разбор
- Заменяет представления (
VIEW) на их определения и обрабатывает правила, определённые для таблиц. - Проверяет права пользователя на объекты.
- Вся необходимая для семантического анализа информация хранится в системном каталоге.
- Семантический анализатор получает от синтаксического дерево разбора и перестраивает его, дополняя ссылками на конкретные объекты БД, указанием типов данных и другой информацией.
Планирование
- Любой запрос можно выполнить разными способами.
- План выполнения также представляется в виде дерева, но его узлы содержат не логические, а физические операции над данными.
- Текстовое представление плана выводит команда
EXPLAIN. - Планировщик (planner) принимает переписанное дерево запроса и генерирует один или несколько вариантов выполнения.
- Оптимизатор оценивает стоимость каждого варианта плана, используя статистику о таблицах, и выбирает наиболее выгодный.
Планы
- Количество возможных планов экспоненциально зависит от количества соединяемых таблиц.
- Для сокращения пространства перебора традиционно используется динамическое программирование в сочетании с эвристиками.
- Точное решение задачи оптимизации не гарантирует, что найденный план действительно будет лучшим (оценки могут быть неточны).
Выбор лучшего плана: общие и частные планы
При выполнении подготовленных запросов (PREPARE) план может быть сохранён и повторно использован:
- Общий план (generic plan) — строится один раз, без учёта конкретных значений параметров.
- Частный план (custom plan) — создаётся при каждом выполнении и учитывает конкретные значения параметров.
При первом выполнении подготовленного запроса PostgreSQL планирует его с учётом переданных параметров (частный план). Однако, если запрос выполняется многократно, система может перейти к общему плану. Если общий план оказывается более выгодным по суммарным затратам, PostgreSQL будет использовать его для последующих вызовов.
Выполнение
- После выбора оптимального плана исполнитель запускает последовательность операций, предусмотренных планом, последовательно проходя по узлам.
- Доступ к данным осуществляется через буферный менеджер, который минимизирует количество операций ввода-вывода на диск.
- Если запрос рассчитан на параллельное выполнение, результат собирается из нескольких рабочих процессов и объединяется в итоговый набор данных.
Статистика
Статистика — набор данных, который собирается системой для оценки распределения значений в таблицах и столбцах, что затем используется планировщиком запросов для выбора наиболее эффективного плана.
Хранение
- PostgreSQL хранит собранную статистику в системной таблице
pg_statistic. - Прямой доступ к
pg_statisticобычно не требуется — для просмотра статистики используют представлениеpg_stats. pg_stats— публичное представление, предоставляющее информацию изpg_statisticв удобном виде, без избыточных деталей, доступных только суперпользователям.- Базовая статистика уровня отношения хранится в таблице
pg_class.
Какие данные собираются
reltuples— число кортежей в отношении.n_distinct— оценка количества уникальных значений.most_common_valsиmost_common_freqs— список наиболее часто встречающихся значений и их частоты.histogram_bounds— границы гистограммы распределения значений, используются для оценки селективности диапазонных запросов.correlation— оценка корреляции между порядком значений в столбце и порядком их физического хранения.null_frac— доля неопределённых (NULL) значений.
Сбор статистики
- Статистика собирается при
ANALYZE— ручном или автоматическом. Также базовая статистика рассчитывается при выполнении некоторых операций (VACUUM FULL,CLUSTER,CREATE INDEX,REINDEX) и уточняется при очистке. - Для анализа случайно выбираются
300 × default_statistics_targetстрок. Размер выборки, достаточной для построения статистики заданной точности, слабо зависит от объёма анализируемых данных, поэтому размер таблицы не учитывается.
pg_stats: использование частых значений и корреляции
- Для уточнения оценки при неравномерном распределении собирается статистика по наиболее часто встречающимся значениям и частоте их появления (
most_common_vals/most_common_freqs). - Список частых значений используется и для оценки селективности условий с неравенствами. Например, для условия
столбец < значение: надо найти вmost_common_valsвсе значения, меньшие искомого, и просуммировать их частоты изmost_common_freqs. - Поле
correlationпоказывает корреляцию между физическим расположением данных и логическим порядком (в смысле операций сравнения):- значения хранятся строго по возрастанию → корреляция близка к
+1; - по убыванию → к
-1; - чем более хаотично расположены данные на диске — тем ближе к
0.
- значения хранятся строго по возрастанию → корреляция близка к
- Корреляция используется для оценки стоимости индексного сканирования.
Табличные методы доступа
Последовательное сканирование (Seq Scan)
- Полностью читается файл основного слоя таблицы. На каждой прочитанной странице проверяется видимость каждой версии строки.
- Чтение происходит через буферный кеш; чтобы большие таблицы не вытесняли полезные данные, используется кольцевой буфер. Другие процессы, одновременно сканирующие ту же таблицу, присоединяются к кольцу и тем самым экономят операции дисковых чтений. Поэтому в общем случае сканирование может стартовать не с начала файла.
- Последовательное сканирование — самый эффективный способ прочитать всю таблицу или значительную её часть. То есть оно хорошо работает при низкой селективности условия.
Оценка стоимости
В оценке стоимости оптимизатор учитывает две составляющие — дисковый ввод-вывод и ресурсы процессора:
- Стоимость ввода-вывода = число страниц в таблице × стоимость чтения одной страницы (при последовательном чтении).
- Стоимость процессора учитывает обработку каждой версии строки (определяется параметром
cpu_tuple_cost). - Соотношение по умолчанию подходит для HDD-дисков. Для SSD имеет смысл существенно уменьшить значение параметра
random_page_cost(значениеseq_page_cost, как правило, не трогают, оставляя единицу в качестве опорного значения). - Если на сканируемую таблицу наложены условия, они отображаются в плане под узлом
Seq Scanв секцииFilter. Оценка числа строк учитывает селективность этих условий, а оценка стоимости — затраты на их вычисление.
Parallel Seq Scan
- Чтение выполняется несколькими параллельно работающими процессами.
- Процессы синхронизируются между собой через специально отведённый участок общей памяти, чтобы не прочитать одну и ту же страницу дважды.
Gather и Gather Merge
Gather— собирает результаты от параллельных рабочих процессов.Gather Merge— параллельные процессы выполняют сортировку локально, аGather Mergeобъединяет уже отсортированные потоки, гарантируя отсортированный итоговый результат без дополнительной сортировки на этапе объединения.
Сканирование только индекса (Index Only Scan)
- Операция представляется в плане узлом
Index Only Scan. - На оценку влияет доля табличных страниц, отмеченных в карте видимости (visibility map): только для них можно не обращаться к самой таблице.
Сканирование по битовой карте (Bitmap Scan)
- Ограничение обычного индексного сканирования: при уменьшении корреляции увеличивается количество обращений к страницам, а характер чтения меняется с последовательного на случайный.
- Bitmap Scan строит битовую карту нужных страниц, а затем читает страницы по порядку — это позволяет вернуться к последовательному характеру чтения.
Сравнение методов доступа
- Зависимость стоимости различных методов доступа от селективности условий — это «вилка»: при высокой селективности выигрывает индексное сканирование, при низкой — последовательное.
- Стоимость индексного сканирования сильно зависит от корреляции. При идеальной корреляции индексное сканирование эффективно даже при довольно большой доле выбираемых строк.
Агрегация
- Hash Aggregation — строит хеш-таблицу по ключам группировки.
- Group Aggregate:
- входные данные должны быть отсортированы по ключам группировки;
- данные читаются в отсортированном порядке, и когда встречается новое значение ключа, текущая группа завершается;
- не требует хранения всей хеш-таблицы в памяти.
CTE (Common Table Expressions)
Идея: если какой-то вложенный подзапрос используется в запросе несколько раз, его можно определить как общее табличное выражение (
WITH ... AS (...)) и ссылаться на него столько раз, сколько потребуется. В этом случае PostgreSQL вычисляет результаты один раз и повторно использует их при повторных обращениях.
Shared Buffers
Оперативная память, где PostgreSQL хранит копии страниц таблиц и индексов.
Когда запрос требует доступ к данным, сервер сначала ищет их в этом кэше. Если страница найдена (cache hit), запрос выполняется быстрее, чем при обращении к диску (cache miss).
EXPLAIN
Команда EXPLAIN показывает план выполнения запроса. Что в нём важно:
- Тип операций (узлов) плана (
Seq Scan,Index Scan,Hash Join, …). - Оценка стоимости (
cost) в форматеcost=START_COST..END_COST. - Оценка количества строк (
rows). - Размер данных (
width). - Параллельное выполнение.
При EXPLAIN ANALYZE дополнительно:
- Фактическое время выполнения — время, затраченное на каждую операцию.
- Фактическое количество строк — сколько строк реально обработано на каждом этапе.
- Число циклов / итераций.
Виды и способы соединений
Соединение хешированием (Hash Join)
- Реализация использует динамически расширяемую хеш-таблицу с разрешением коллизий цепочками (как для буферного кеша).
- Очень эффективно для больших наборов данных. При достаточном объёме оперативной памяти требует однократного просмотра двух наборов данных — то есть имеет линейную сложность.
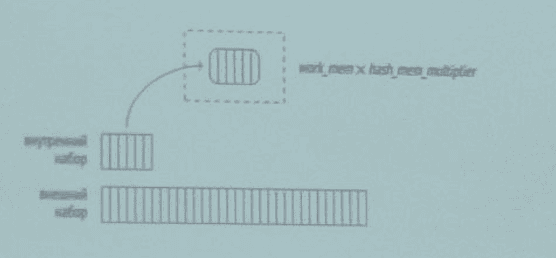
Соединение хешированием в параллельных планах

Соединение слиянием (Merge Join)
- Работает для наборов данных, отсортированных по ключу соединения, и возвращает отсортированный же результат.
- Входной набор может оказаться уже отсортированным в результате индексного сканирования или быть отсортирован явно.
- Используются алгоритмы: быстрая сортировка, частичная пирамидальная сортировка, внешняя сортировка слиянием (если данные не помещаются в память).
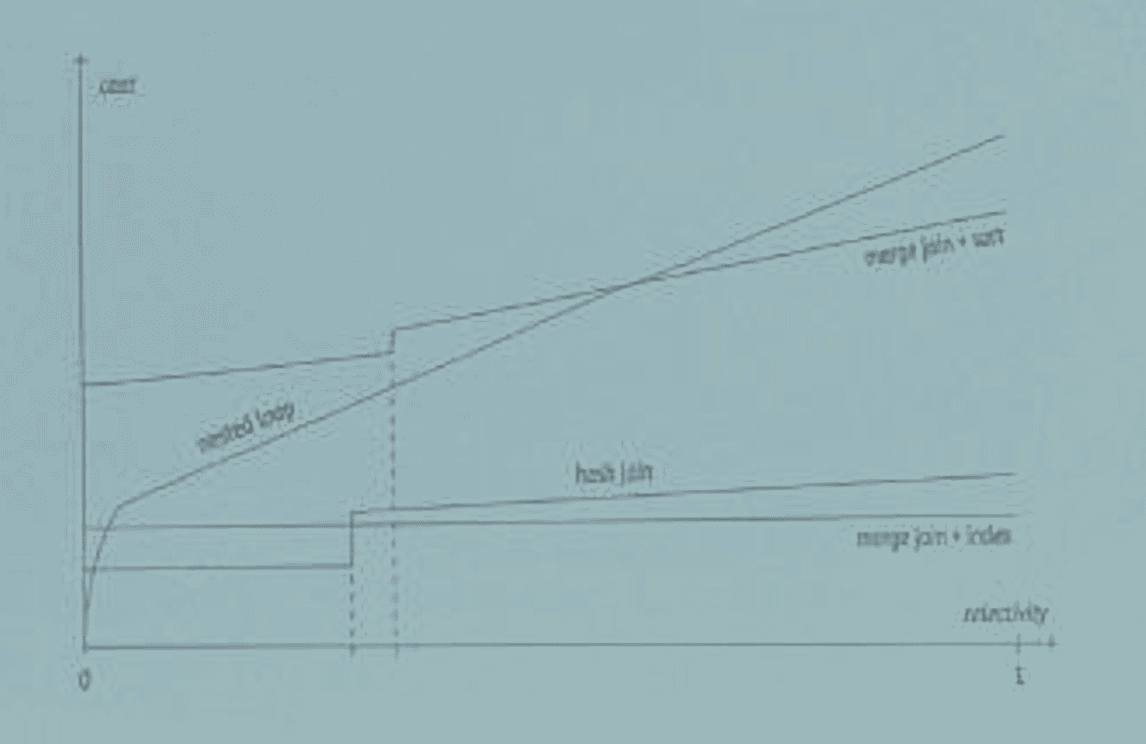
Соединение вложенным циклом (Nested Loop Join)
На эффективность Nested Loop Join влияют несколько условий:
- кардинальность внешнего набора строк;
- наличие метода доступа ко внутреннему набору, позволяющего эффективно получить нужные строки;
- повторные обращения к одним и тем же строкам внутреннего набора.
Полная стоимость соединения складывается из:
- стоимости получения всех строк внешнего набора;
- однократной стоимости первоначального получения всех строк внутреннего набора (в ходе которого выполняется материализация);
- $(N-1)$-кратной стоимости повторного получения строк внутреннего набора;
- стоимости обработки каждой строки результата.
Сортировки
- PostgreSQL использует quicksort, чтобы выполнить операцию в оперативной памяти. Размер выделенной памяти контролируется параметром
work_mem. - Если объём данных превышает значение
work_mem, PostgreSQL может производить сортировку с временным сохранением промежуточных результатов на диске (external merge sort). - В новых версиях PostgreSQL поддерживается параллельное выполнение операций сортировки.